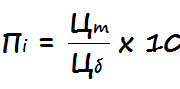Рынок труда аналитиков и data scientists
Содержание:
- Распределение
- Соберем данные
- Как дела обстоят у нас
- Как работают эксперты по аналитическим данным в лаборатории Philips Research
- Что должен знать начинающий Data Scientist?
- Кто такой Data Scientist?
- Data Scientist: кто это и что он делает
- Образование. Шесть шагов на пути к Data Scientist
- Основная работа ведётся на удалённом сервере
- Дорожная карта развития навыков Data Science
- Как стать Data Scientist с нуля?
- Что в итоге
Распределение
Внешняя форма данных, выраженная в мерах описательной статистики, даёт нам информацию об их характере. Это как в жизни: по фигуре, походке и одежде человека обычно можно догадаться о его поле, возрасте и даже профессии. В случае числовых данных мы догадываемся о распределении.
Термин пришёл из теории вероятностей, которая рассматривает любое событие в мире как имеющее ту или иную вероятность. Однородные события хоть и происходят с разной вероятностью, но подчиняются распределению, которое «раздаёт» им эти вероятности.
В Data Science распределение понимается обобщённо: это закон соответствия одной величины другой. Оно подсказывает нам, какой именно процесс может скрываться за данными, и то, насколько эти данные полны. Чуть подробнее об этом в нашей статье про математику для джунов.
Возможно, вы уже слышали про колокол нормального распределения, или гауссиану: она описывает процессы, где результат является суммой многих случайных величин, каждая из которых слабо зависит от другой и вносит сравнительно небольшой вклад.

Распределение размеров чашелистика ириса разноцветного. Изображение: Qwfp / Pbroks13 /
Величина ошибок измерения в физике, длина когтей, зубов и шерсти в биологии, объёмы речных стоков в гидрологии — все эти показатели имеют нормальное распределение. Это, пожалуй, самое распространённое в природе и не только в природе распределение, поэтому оно и названо нормальным.
Распределение Пуассона тоже часто встречается в работе дата-сайентистов и аналитиков: это число событий за какой-то промежуток времени — при условии, что события независимы друг от друга и имеют некоторый порог интенсивности.

При ƛ = 10 горка Пуассона похожа на колокол Гаусса. Будьте внимательны!
Это и число посетителей в торговом центре, и количество голов, забитых футбольной командой, и скорость роста колонии бактерий.
Существуют и , в том числе довольно экзотические: Вигнера, Вейбулла, Коши. Они встречаются намного реже или преимущественно в каких-то специальных областях вроде квантовой физики. Тем не менее дата-сайентисту нужно знать графики, параметры и названия основных распределений, благо их не так много.
Соберем данные
Чтобы не быть голословным, я приведу простой пример. Соберем какие-нибудь данные.
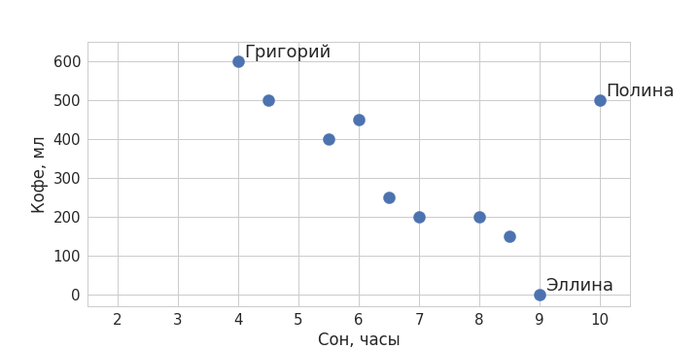
Представьте, что нас интересует, есть ли какая-то взаимосвязь между тем, сколько ваши коллеги по работе выпивают кофе за день, и тем, сколько они спали накануне. Запишем доступную нам информацию: допустим, ваш коллега Григорий сегодня спал 4 часа, так что ему пришлось выпить 3 чашки кофе; Эллина спала 9 часов и не пила кофе вообще; а Полина спала все 10 часов, но выпила 2,5 чашки кофе – и так далее.
Изобразим полученные данные на графике (визуализация – тоже немаловажный элемент любого data science-проекта). Отложим по оси X время в часах, а по оси Y – кофе в миллилитрах. Получим что-то вроде такого:
Как дела обстоят у нас
Мы создаем систему городской мобильности с человеческим отношением к пассажирам и водителям. И хотим сделать это отраслевым стандартом. Хотим встречать и провожать пассажиров в аэропорты и на вокзалы; доставлять важные документы по указанным адресам быстрее курьеров; сделать так, чтобы на такси было не страшно отправить ребёнка в школу или девушку домой после свидания, даем возможность выбрать транспорт — каршеринг, такси или самокат. И даже если нашим пассажиром является котик, то ему должно быть максимально комфортно.
У нас есть большой отдел эффективности платформы (или Marketplace), где в каждом из направлений работают специалисты по обработке и анализу данных.
-
Ценообразование: правильный и правдоподобный предрасчет цены для клиента на предстоящую поездку. Мы разрабатываем алгоритмы, которые тонко настраивают наши цены под специфические региональные и временные условия, а также помогают нам держать вектор оптимального ценового роста и развития
-
Клиентские мотивации: помогают нам привлекать новых клиентов, удерживать старых и делать нашу цену самой привлекательной на рынке. Основное направление — это разработка алгоритма оптимального распределения бюджета на скидки клиентам для достижения максимального количества поездок. Мы стремимся создать выгодное предложение для каждого клиента, поддержать и ускорить наш рост
-
Водительские мотивации: одна из главных задач Ситимобил — забота о водителях. Наши алгоритмы создают для них среду, в которой каждый работает эффективно и зарабатывает много. Мы стремимся разработать подход, позволяющий стимулировать водителей к выполнению поездок там, где другие алгоритмы не справляются: возмещаем простой на линии, если нет заказов, и гарантируем стабильность завтрашнего дня для привлечения всё новых и новых водителей.
-
Динамическое ценообразование: главная задача направления — гарантировать возможность уехать на такси в любое время и в любом месте. Достигается это за счет кратковременного изменения цен, когда желающих уехать больше, чем водителей в определенной гео-зоне.
-
Распределение заказов: эффективные алгоритмы назначения водителей на заказ уменьшают длительность ожидания и повышают заработок водителей. Задача этого направления — создать масштабируемые механизмы назначения, превосходно работающие как в целом по городам, так и в разрезе каждого тарифа.
-
Исследование эффективности маркетплейсов: центральное аналитическое направление, задачей которого является анализ эффективного баланса между количеством водителей на линии и пассажирами.
-
ГЕО сервисы: эффективное использование геоданных помогает различным командам эффективно настраивать свои алгоритмы, которые напрямую зависят от качества этих данных. Мы стремимся создавать такие модели, сервисы и алгоритмы, которые не только повышают качество маршрутизации и гео-поиска, но и напрямую воздействуют на бизнес, а также клиентский опыт.
Как работают эксперты по аналитическим данным в лаборатории Philips Research
В лаборатории Philips Research каждый Data Scientist занимается разработками в рамках текущих проектов компании в сфере здравоохранения. Тематика разработок достаточно широкая, и заниматься в лаборатории можно чем угодно: распознаванием образов и обработкой изображений и текстов, предсказанием болезней, поиском аномалий, генеративными моделями и другими технологиями.
Один из приоритетов специалистов лабораторий Philips Research по всему миру — разработка инновационных подходов к медицинской визуализации. Учёные стремятся автоматизировать некоторые из задач врачей, деятельность которых связана с оценкой изображений, и внедряют ИИ (искуственный интеллект) в рентгенологию, МРТ, компьютерную томографию, патоморфологию.
Примером может послужить возможность создавать один вид изображения на основании другого — этому могут обучаться генеративные алгоритмы. Нейросети моделируют изображения на основании известной информации: мы знакомы с этой возможностью, по развлекательным мобильным приложениям, в которых можно создать «гибрид» двух людей по фотографиям.
В медицине это применимо, когда пациенту во время обследования требуется сразу две процедуры: компьютерная томография (КТ) и МРТ. При проведении КТ доза облучения пациента несколько выше, особенно когда необходимо хорошее разрешение. Чтобы снизить уровень лучевой нагрузки, особенно, если пациент — ребенок, ученые создали метод, который называется квази-КТ. Согласно ему обученная программа генерирует КТ на основе существующих МРТ. Пациент проходит одну процедуру вместо нескольких. Таким образом уменьшается время и стоимость обследования, а главное — доза облучения.
Среди направлений разработок Philips Research, не связанных с визуализацией, особенно перспективна прогнозная аналитика — предсказание заболеваний в зависимости от местности и группы населения. Если будут учитываться медицинские показатели миллионов человек, можно будет находить взаимосвязи и закономерности, выяснять, почему где-то одни заболевания распространены больше, чем другие, и затем на основании полученной информации определять группы риска и проводить профилактику до возникновения вспышек болезней.
Специалисты Philips Research принимают участие в разработке интеллектуальных систем, занимаются изобретательской деятельностью с последующим патентованием. К тому же специалисты проводят исследования, экспериментируют с данными и оформляют свои результаты в виде научных статей и выступают с докладами на ведущих мировых конференциях в сфере искусственного интеллекта, таких как MICCAI, MIDL, ACPR.
Data Scientist на сегодня — одна из самых быстроразвивающихся профессий, которая позволяет претворять в жизнь то, что раньше казалось нереальным. Спрос на специалистов в области данных велик и продолжает расти, а возможности для развития практически безграничны.
Что должен знать начинающий Data Scientist?
Data scientist должен уметь писать код. Специалист по данным занимается написанием модели для оценки гипотез, аналитики или оценки данных. Этого никак не сделать без знаний основных языков программирования, применяемых в области Data Science. Вам пригодятся знания:
- Java, Hive для работы с Hadoop;
- Python – его основы и понимание того, как работать с ним в анализе данных. Также познакомьтесь с инструментами Matplotlib, Numpy, Scikit, Skipy;
- SQL – для извлечения данных;
- C++ с инструментами BigARTM, Vowpel Wabbit, XGBoost;
- языка R, который пригодится для расчетов статистики.
Математика.
Аналитик данных должен пройти курсы математического анализа, математической статистики, линейной алгебры, а также знать, что такое теория вероятности. Эти знания пригодятся, для того чтобы составлять прогнозы, работать над поиском закономерностей и построением математических моделей.
В математическом анализе вам понадобятся производные, правило дифференцирования сложной функции и градиенты. Описательная статистика, планирование эксперимента и машинное обучение нужно будет изучить в курсе математической статистики
Линейная алгебра нужна для понимания механизмов машинного обучения, там обратите внимание на векторы и пространства, матричные преобразования.
Машинное обучение.
Без него в вашей работе никуда. Машинное обучение нужно для создания новых моделей и переобучения существующих. Также оно связано не только с искусственным интеллектом, но и с генетическими, эволюционными алгоритмами, кластерными задачами и так далее. Благодаря машинному обучению работа Data Scientist с большими объемами данных становится эффективной.
Deep Learning.
Чтобы руководить проектами машинного обучения, вам нужно будет разобраться, как устроены нейронные сети и изучить основы глубокого обучения.
Специфику домена.
Для того чтобы понимать, как работает продукт и создавать подходящую модель, необходимы знания о домене, в котором вы работаете. Data Scientists трудятся во всевозможных отраслях, самыми популярными из которых являются маркетинг, здравоохранение и экономика. Если у вас нет нужных профильных знаний заранее, не переживайте, вы точно приобретете их на проекте.
Английский язык.
Обязательный пункт для любой специальности в ИТ. Английский пригодится вам в работе при общении с зарубежными клиентами и коллегами в многонациональной команде. Также вы столкнетесь с английским во время работы с различными фреймворками и технологиями, и в своем развитии: много технической литературы выпускается только на английском языке.
Если вы уже работаете в Data Science, то наверняка знакомы со всеми этими требованиями. Для опытных аналитиков данных они, конечно же, другие.
Требования к опытному специалисту по данным
Некоторые специалисты описывают успешного Data Scientist как хакера, аналитика, коммуникатора или доверенного консультанта. Давайте разберемся, какие скиллы вам пригодятся.
Кроме hard skills, которые мы описывали выше, вам нужно иметь:
- Опыт разработки моделей машинного и глубинного обучения с фреймворками Hadoop, TensorFlow, Keras, PyTorch, Scikit-Learn, Pytorch, MLLib и другими;
- Глубокие знания одной из областей обучения по прецедентам Machine Learning;
- Опыт работы с SQL и инструментами BigData, как Spark/Hive;
- Опыт работы с инструментами визуализации Pandas, Matplotlib, Seaborne.
Конечно, работа в команде требует развитых гибких навыков для Data Scientist. Давайте рассмотрим, какие навыки вам помогут.
Soft skills для Data Scientist
- Ассоциативное мышление.
- Способность излагать свои мысли так, чтобы их понял другой человек.
- Любопытство для погружения в проблему и дальнейшей работы с гипотезами.
- Умение находить эффективные решения проблем.
- Внимательность.
- Умение работать в команде и находить подход к каждому.
- Умение задавать хорошие вопросы.
- Дотошность.
- Умение визуализировать данные.
С требованиями и навыками разобрались. А теперь давайте узнаем, какие нам пригодятся курсы, видео и материалы, чтобы развиваться в Data Science?

Кто такой Data Scientist?
Давайте начнем наше знакомство с профессией с области, в которой работают Data Scientists. Data Science – это наука о данных, которая занимается изучением данных, их анализом различными методами и последующим преобразованием данных в полезные знания. Раньше обработать данные человек мог вручную, но сейчас их количество стало настолько огромным, что для обработки часто требуется искусственный интеллект. Поэтому наука активно взаимодействует с машинным обучением, математикой, статистикой и анализом данных.
Нас постоянно окружают результаты работы Data Scientists, например, мы ежедневно смотрим прогноз погоды, реклама предлагает нам определенные товары, авиасервисы прогнозируют стоимость билетов, врачи с помощью программ могут предсказать диагнозы, а голосовые помощники выполняют множество наших просьб. Всем этим и многими другими вещами управляет специалист по данным. Data Scientist – это специалист, который занимается поиском закономерностей в больших массивах данных, анализирует и хранит их. Профессия Data Scientist считается одной из самых высокооплачиваемых и сложных в мире ИТ.
Стоит обратить внимание на то, что Data Science стала неотъемлемой частью будущего. Сейчас ее активно используют в стартапах, IT компаниях, различных бизнесах, чтобы предоставлять наиболее точные данные и прогнозы, быть ближе к пользователю, автоматизировать свои решения и повысить маржинальность бизнеса
Спрос на Data Scientists ежегодно растет. Например, по информации веб-сайта по поиску работы Indeed, за 2019 год вакансий Data Scientists стало на 29% больше.
Data Scientists постоянно ищут паттерны и тренды в огромных наборах данных, используя многообразные тулы, техники и критическое мышление, чтобы найти практическое решение для реальных data-centric проблем. Давайте подробнее поговорим о том, что входит в обязанности специалистов по данным.

Data Scientist: кто это и что он делает
В переводе с английского Data Scientist – это специалист по данным. Он работает с Big Data или большими массивами данных.
Источники этих сведений зависят от сферы деятельности. Например, в промышленности ими могут быть датчики или измерительные приборы, которые показывают температуру, давление и т. д. В интернет-среде – запросы пользователей, время, проведенное на определенном сайте, количество кликов на иконку с товаром и т. п.
Данные могут быть любыми: как текстовыми документами и таблицами, так и аудио и видеороликами.
От области деятельности зависят и результаты работы Data Scientist. После извлечения нужной информации специалист устанавливает закономерности, подвергает их анализу, делает прогнозы и принимает бизнес-решения.
Человек этой профессии выполняет следующие задачи: оценивает эффективность и работоспособность предприятия, предлагает стратегию и инструменты для улучшения, показывает пути для развития, автоматизирует нудные задачи, помогает сэкономить на расходах и увеличить доход.
Его труд заканчивается созданием модели кода программы, сформировавшейся на основе работы с данными, которая предсказывает самый вероятный результат.
Профессия появилась относительно недавно. Лишь десятилетие назад она была официально зафиксирована. Но уже за такой короткий промежуток времени стала актуальной и очень перспективной.
Каждый год количество информации и данных увеличивается с геометрической прогрессией. В связи с этим информационные массивы уже не получается обрабатывать старыми стандартными средствами статистики. К тому же сведения быстро обновляются и собираются в неоднородном виде, что затрудняет их обработку и анализ.
Вот тут на сцене и появляется Data Scientist. Он является междисциплинарным специалистом, у которого есть знания статистики, системного и бизнес-анализа, математики, экономики и компьютерных систем.
Знать все на уровне профессора не обязательно, а достаточно лишь немного понимать суть этих дисциплин. К тому же в крупных компаниях работают группы таких специалистов, каждый из которых лучше других разбирается в своей области.
Эти знания помогают ему выполнять свои должностные обязанности:
- взаимодействовать с заказчиком: выяснять, что ему нужно, подбирать для него подходящий вариант решения проблемы;
- собирать, обрабатывать, анализировать, изучать, видоизменять Big Data;
- анализировать поведение потребителей;
- составлять отчеты и делать презентации по выполненной работе;
- решать бизнес-задачи и увеличивать прибыль за счет использования данных;
- работать с популярными языками программирования;
- моделировать клиентскую базу;
- заниматься персонализацией продуктов;
- анализировать эффективность деятельности внутренних процессов компании;
- выявлять и предотвращать риски;
- работать со статистическими данными;
- заниматься аналитикой и методами интеллектуального анализа;
- выявлять закономерности, которые помогают организации достигнуть конечной цели;
- программировать и тренировать модели машинного обучения;
внедрять разработанную модель в производство.
Четких границ требований к Data Scientist нет, поэтому работодатели часто ищут сказочное создание, которое может все и на превосходном уровне. Да, есть люди, которые отлично понимают статистику, математику, аналитику, машинное обучение, экономику, программирование. Но таких специалистов крайне мало.
Еще часто Data Scientist путают с аналитиком. Но их задачи несколько разные. Поясню, что такое аналитика и как она отличается от деятельности Data Scientist, на примере и простыми словами.
В банк пришел клиент, чтобы оформить кредит. Программа начинает обрабатывать данные этого человека, выясняет его кредитную историю и анализирует платежеспособность заемщика. А алгоритм, который решает выдавать кредит или нет, – продукт работы Data Scientist.
Аналитик же, который работает в этом банке, не интересуется отдельными клиентами и не создает технические коды и программы. Вместо этого он собирает и изучает сведения обо всех кредитах, что выдал банк за определенный период, например, квартал. И на основе этой статистики решает, увеличить ли объемы выдачи кредитов или, наоборот, сократить.
Аналитик предлагает действия для решения задачи, а Data Scientist создает инструменты.
Образование. Шесть шагов на пути к Data Scientist
Путь к этой профессии труден: невозможно овладеть всеми инструментами за месяц или даже год. Придётся постоянно учиться, делать маленькие шаги каждый день, ошибаться и пытаться вновь.
Шаг 1. Статистика, математика, линейная алгебра
Для серьезного понимания Data Science понадобится фундаментальный курс по теории вероятностей (математический анализ как необходимый инструмент в теории вероятностей), линейной алгебре и математической статистике.
Фундаментальные математические знания важны, чтобы анализировать результаты применения алгоритмов обработки данных. Сильные инженеры в машинном обучении без такого образования есть, но это скорее исключение.
Что почитать
«Элементы статистического обучения», Тревор Хасти, Роберт Тибширани и Джером Фридман — если после учебы в университете осталось много пробелов. Классические разделы машинного обучения представлены в терминах математической статистики со строгими математическими вычислениями.
«Глубокое обучение», Ян Гудфеллоу. Лучшая книга о математических принципах, лежащих в основе нейронных сетей.
«Нейронные сети и глубокое обучение», Майкл Нильсен. Для знакомства с основными принципами.
Полное руководство по математике и статистике для Data Science. Крутое и нескучное пошаговое руководство, которое поможет сориентироваться в математике и статистике.
Введение в статистику для Data Science поможет понять центральную предельную теорему. Оно охватывает генеральные совокупности, выборки и их распределение, содержит полезные видеоматериалы.
Полное руководство для начинающих по линейной алгебре для специалистов по анализу данных. Всё, что необходимо знать о линейной алгебре.
Линейная алгебра для Data Scientists. Интересная статья, знакомящая с основами линейной алгебры.
Шаг 2. Программирование
Большим преимуществом будет знакомство с основами программирования. Вы можете немного упростить себе задачу: начните изучать один язык и сосредоточьтесь на всех нюансах его синтаксиса.
При выборе языка обратите внимание на Python. Во-первых, он идеален для новичков, его синтаксис относительно прост. Во-вторых, Python многофункционален и востребован на рынке труда.
Что почитать
«Автоматизация рутинных задач с помощью Python: практическое руководство для начинающих». Практическое руководство для тех, кто учится с нуля. Достаточно прочесть главу «Манипулирование строками» и выполнить практические задания из нее.
Codecademy — здесь вы научитесь хорошему общему синтаксису.
Легкий способ выучить Python 3 — блестящий мануал, в котором объясняются основы.
Dataquest поможет освоить синтаксис.
The Python Tutorial — официальная документация.
После того, как изучите основы Python, познакомьтесь с основными библиотеками:
- Numpy : документация — руководство
- Scipy : документация — руководство
- Pandas : документация — руководство
Визуализация:
- Matplotlib : документация — руководство
- Seaborn : документация — руководство
Машинное обучение и глубокое обучение:
- SciKit-Learn: документация — руководство
- TensorFlow : документация — руководство
- Theano : документация — руководство
- Keras: документация — руководство
Обработка естественного языка:
NLTK — документация — руководство
Web scraping (Работа с web):
BeautifulSoup 4 — документация — руководство
Основная работа ведётся на удалённом сервере
Большинство людей начинают своё путешествие по Data Science на персональных компьютерах. Однако в реальных проектах зачастую требуется гораздо большая вычислительная мощность, которую не сможет обеспечить ни ноутбук, ни даже игровой ПК. Поэтому исследователи Data Science используют свои компьютеры для доступа к удалённому серверу по SSH (Secure Shell). SSH позволяет безопасно подключиться к вычислительной машине. После установки соединения удалённый сервер можно использовать как командную оболочку вашего компьютера. Поэтому при работе с сервером пригодится знание основных команд для Linux и опыт использования терминала.
Дорожная карта развития навыков Data Science
Итак, чтобы стать специалистом базового уровня, понадобится от 6 до 12 месяцев. Вырасти с базового уровня до среднего можно за 7–18 месяцев. Продвинутый уровень потребует ещё от 18 до 48 месяцев.

Конечно, это приблизительные сроки. Многое зависит от бэкграунда: тем, кто неплохо прокачан в физике, математике, естественных и компьютерных науках, работал инженером или финансистом, будет гораздо проще. Но в первую очередь важны усилия и время, которые вы вкладываете в изучение Data Science, — в общем, никакой магии. Просто берём и делаем.
На курсе «Профессии Data Scientist» мы даём не только базовые знания, но и часть навыков среднего и продвинутого уровней. В итоге у вас появятся портфолио проектов, стаж не менее года, заряженные единомышленники и компетентные наставники. Приходите!
Как стать Data Scientist с нуля?
Давайте разберемся, с чего начать обучение профессии, и как можно стать специалистом по анализу данных.
- Первый способ – поступить в профильный вуз и параллельно освоить необходимые языки программирования и инструменты визуализации. Есть несколько вузов, выпускники которых особенно ценятся среди работодателей.
- Второй способ – пойти на курсы, где вы изучите математическую базу и получите практические навыки. Если у вас уже есть техническое образование, пусть даже не связанное с Data Scientist, это оптимальный вариант. Если технического образования нет, то найти первую работу будет сложнее. Вам могут помочь курсы, где есть программы помощи с трудоустройством.
-
Часто в профессию переходят аналитики данных и Python-разработчики. Сфера активно растет, поэтому людей привлекают высокие зарплаты и перспективы.
Также освоить профессию Data Scientist можно через интернет. Многие люди, которые ищут, с чего начать карьеру в этой сфере, выбирают данный путь. Есть несколько онлайн-университетов, где можно пройти обучение:
|
Название курса и ссылка на него |
Описание |
|
Профессия Data Scientist в Skillbox |
Курс в университете Skillbox. Подходит новичкам и людям без опыта работы в IT. Вы изучите теорию (анализ данных, Machine Learning, статистика, теория вероятностей, функции, работа с производными и многое другое), научитесь программировать на Python и языке R, изучите библиотеки Pandas, NumPy и Matplotlib, работу с базами данных. Сможете создавать рекомендательные системы, применять нейронные сети для решения задач, визуализировать данные. Включает практические задания. На защите диплома присутствуют работодатели. |
|
Обучение Data Scientist в Нетологии (уровень – с нуля) |
Курс походит людям, которые хотят сменить текущую профессию на Data Scientist. Включает программу помощи с трудоустройством. Изучают математику для анализа данных, построение моделей, управление data-проектами, Python, базы данных, обработку естественного языка (NLP) и многое другое. Объема полученных знаний хватит для старта в карьере. Преподаватели – сотрудники крупных ИТ и финансовых компаний. |
В интернете есть бесплатные курсы по Data Scientist. Если вы думаете, подойдет или нет вам эта профессия, то можете посмотреть данные уроки и получить более полное представление и описание данной работы:
- Анализ данных на Python в задачах и примерах
- Курс по библиотеке Pandas
- Курс по машинному обучению для новичков
- Бесплатный курс по базам данных MySQL
-
Работа с Google Таблицами для начинающих
Что в итоге
Если помнить про целостный подход и четыре компонента обучения сложному навыку, получится не только брать лучшее из статей и блогов по Data Science, но и грамотно составлять собственные планы изучения конкретного сложного навыка. Как это сделать:
- Составьте список необходимых простых навыков. Их несложно нагуглить.
- Пропишите сценарии применения этих простых навыков в рамках сложного. Скорее всего, надо будет обратиться к специализированным блогам, форумам, книгам, подкастам.
- Научитесь применять каждый навык изолированно, опираясь на инструкции, руководства и документацию. Как правило, их можно найти на официальных сайтах или в блогах разработчиков.
- Составьте серии задач с увеличением сложности, для решения которых каждый раз будет требоваться всё больше простых навыков. Поиск в интернете по фразе «<название навыка> + задачи» даст вам начальные ориентиры.

Когда составите список, посоветуйтесь с наставником или единомышленниками, чтобы понять, какие задачи стоит убрать, а каких не хватает.
Далее следуйте плану. А собранные материалы станут отличной основой для поста в блог, Telegram-канала, подкаста или видео — так вы поможете другим людям и повысите свой статус.
Если вы ещё не готовы составить свой план обучения, выберите готовую сбалансированную программу — например, наш курс «Профессия Data Scientist». Здесь уже есть всё, что нужно: списки навыков, инструкции и руководства, серии задач и проектов, а также чаты единомышленников и опытные наставники.