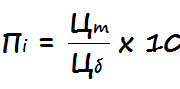Сайт закрыт от индексации: это не повод для паники
Содержание:
- Введение
- Как закрыть сайт от индексации с помощью robots.txt
- Инструмент проверки индексации от PromoPult
- Как узнать сколько страниц в дополнительном индексе?
- Результаты эксперимента: AJAX
- Как проверить работу robots.txt
- Блокировка доступа поисковым системам с помощью mod_rewrite
- Пять вариантов закрыть дубли на сайте от индексации Яндекс и Google
- Операторы в robots.txt
- Запрет индексации страницы или раздела
- Как закрыть сайт от индексации с помощью мета-тэга
- Как в Битрикс закрыть сайт от индексации
- Закрытие от индексации элементов на страницах сайта
- Внутренние ссылки
- Как закрыть внешние, исходящие ссылки от индексации на WordPress
- Используемые директивы
Введение
Технические аспекты созданного сайта играют не менее важную роль для продвижения сайта в поисковых системах, чем его наполнение. Одним из наиболее важных технических аспектов является индексирование сайта, т. е. определение областей сайта (файлов и директорий), которые могут или не могут быть проиндексированы роботами поисковых систем. Для этих целей используется robots.txt – это специальный файл, который содержит команды для роботов поисковиков. Правильный файл robots.txt для Яндекса и Google поможет избежать многих неприятных последствий, связанных с индексацией сайта.
Как закрыть сайт от индексации с помощью robots.txt
Правильно настроенные допуск/недопуск поисковых роботов к ресурсу или его части являются важными и востребованными аспектами для разработчиков и владельцев. Есть в этой теме решения, ставшие классикой. К их числу, несомненно, относится создание служебного файла robots.txt.
Уже из названия понятно, что файл представляет собой какой-то текст, предназначенный для роботов. Все верно. Остается только пояснить, что «какой-то текст» — это набор директив, позволяющий паукам осуществлять целенаправленную работу по индексированию: они посещают разрешенные страницы и игнорируют запрещенные.

Общение с ресурсом роботы начинают с обращения к robots.txt, предназначенному специально для них. Если файл отсутствует или не содержит указаний для пауков, они приступят к сканированию всех страниц сайта, так как иное не обозначено в документе.
Рекомендуемые статьи по данной теме:
- Внутренняя оптимизация сайта: пошаговый разбор
- RSS на сайте: насколько актуален этот инструмент и как правильно им пользоваться
- Редирект с http на https: повышаем безопасность сайта
В файле robots.txt закрыть сайт от индексации можно самостоятельно, вовсе не обязательно привлекать для этого специалиста. Представьте или нарисуйте схему своего ресурса: от корня расходятся несколько линий – это пути, ведущие к папкам, страницам, категориям. Определите, какие из них не должны видеть пользователи, получая выдачу на запрос. Теперь поставьте знак STOP перед роботами. Для этого вносятся соответствующие коррективы в robots.txt, содержащий «визитную карточку» робота (User-agent) и собственно запрет (Disallow).
Приступаем.
Обозначаете поисковую систему.
User-agent: * (все системы).
User-agent: Yandex (для «Яндекса»).
User-agent: Googlebot (для «Гугла»).
Аналогичным образом указывается любой поисковый робот, которых на сегодня известно более трехсот.
Вписываете запрещенные к индексированию компоненты.
Обратите внимание, что разрешение на сканирование страниц оформляется следующей записью:
Disallow:
При этом запрет выглядит так (для всех страниц):
Disallow: /
Для содержимого одноименной папки:
Disallow: /images/
Для изображений указанного формата: каждый запрещенный к индексации формат вписывается отдельной строкой.
Disallow: *.webp
Для документов указанного формата: каждый формат – в отдельной строке.
Disallow: *.doc
Для конкретного файла: каждый файл, который не нужно индексировать, записывается на отдельной строке.
Disallow: /myfile1.htm
Следует крайне внимательно относиться к заполнению инструкции robots.txt, руководствуясь принципом «не навреди», ведь даже мелкий недочет может стать причиной серьезных проблем для ресурса. Количество команд не может превышать отметку в 1024.
Инструмент проверки индексации от PromoPult
Для быстрой проверки индексации онлайн в Яндексе и Google в PromoPult разработали инструмент для анализа индексации страниц.
Что он умеет:
- одновременно проверять проиндексированные страницы в Яндексе и Google (или только одной из тих ПС);
- проверять сразу все URL сайта из XML-карты;
Особенности инструмента:
- работа «в облаке»;
- выгрузка отчетов в формате XLSX;
- уведомление на почту об окончании сбора данных;
- хранение отчетов неограниченное время на сервере PromoPult;
- нет ограничений по количеству URL.
Как проверить индексацию страниц с помощью инструмента PromoPult
Шаг 1. Добавьте URL на проверку
Перейдите на страницу инструмента и добавьте URL, которые нужно проверить. Делается это одним из трех способов:
Добавление XML-карты сайта (вариант подходит, если вам нужно проверить все URL сайта; для этого укажите полный путь к карте сайта в формате http://www.site.ru/sitemap.xml).

Загрузка XLSX-файла (в этом случае система проверит все URL, указанные на первом листе сайта; расположение URL по столбцам и строкам не имеет значения).

Добавление списка URL вручную (вариант подходит, если вам нужно проверить не все URL сайта, а только некоторые из них; каждый URL прописывайте с новой строки).

В зависимости от того, из какого источника вы будете брать URL, решаются разные задачи.
Из XML-карты сайта или CMS
В этом случае можно проверить, какие из важных URL не проиндексированы.
Пример. В карте сайта 1250 URL, которые подлежат индексации. Мы вводим поочередно в Яндексе и Google команду:
site:yourdomain.ru
Получаем количество проиндексированных страниц – 684 и 1090.
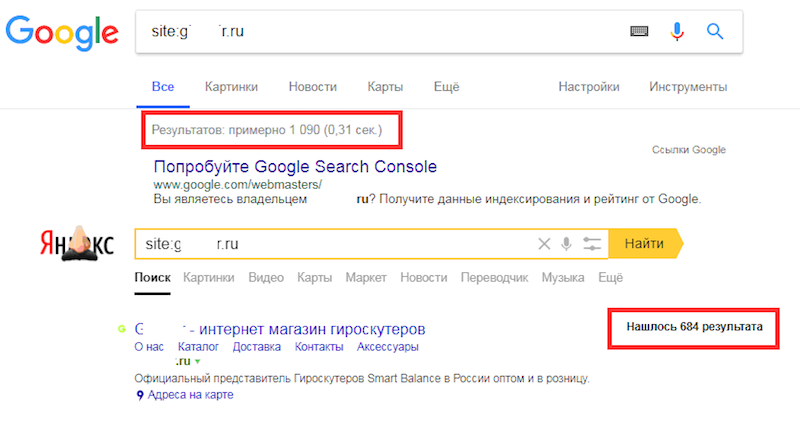
Задача – определить, каких страниц не хватает. Сканируем XML-карту сайта с помощью инструмента от PromoPult, получаем информацию по всем URL и выявляем несоответствия.
Из отчета о проиндексированных страницах из Яндекс.Вебмастера или Google Search Consol
Бывает, что в каком-то поисковике количество проиндексированных страниц превышает количество URL в карте сайта. В такой ситуации необходимо загрузить на проверку все URL из поисковика, в котором наблюдается такое превышение, – это позволит выявить «лишние» страницы.
Пример. В карте сайта 15 570 URL, которые подлежат индексации. Проверяем количество страниц по команде site:yourdomain.ru в Яндексе и Google:
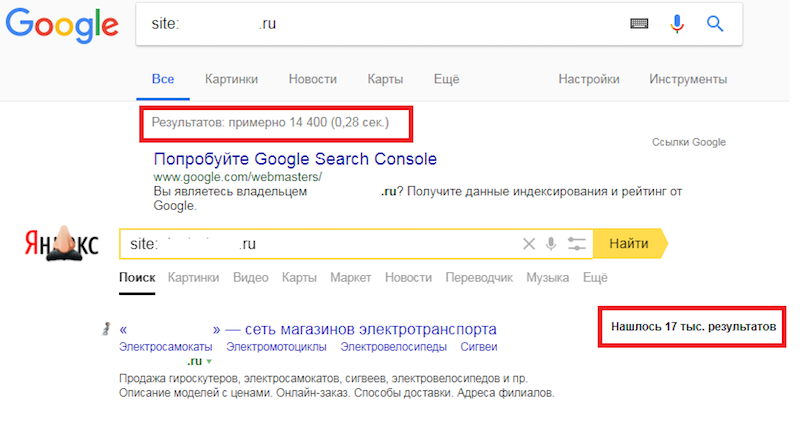
В Яндексе количество страниц превышает количество страниц не только в Google, но и в карте сайта. Очевидно, что в индекс попали нежелательные страницы. Если запустить проверку только по URL из карты, мы так и не узнаем, какие URL «лишние». Поэтому переходим в Яндекс.Вебмастер, выгружаем все страницы из поиска и проверяем их. Теперь проще разобраться, в чем проблема.
На данном этапе выберите ПС для проверки индексации. Для выявления расхождений выберите две системы.

Шаг 3. Загрузка отчета
После проверки отчет появится в «Списке задач». Кроме того, вам на почту придет уведомление:

Загрузите отчет в формате XLSX:

В файле два листа: результаты анализа и исходные данные. На первом листе 3 столбца: URL и данные по индексации (1 – страница проиндексирована, 0 – нет).
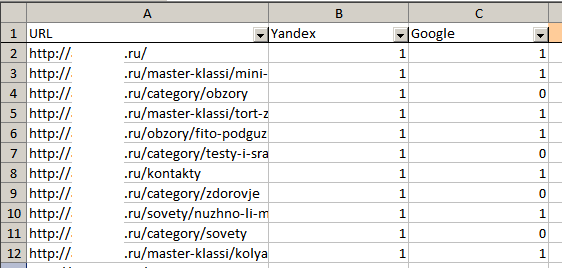
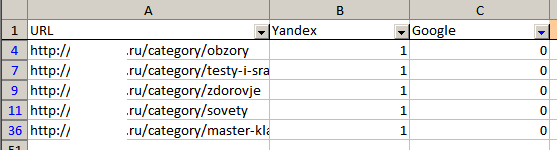
С помощью автофильтра вы легко определите, каких страниц не хватает в Яндексе или Google:
Как узнать сколько страниц в дополнительном индексе?
Тут все относительно просто. Покажу на примере моего блога. Запрос в гугле
Покажет сколько страниц в основном индексе, сейчас их «About 558 results».
Запрос без знаков «/&», покажет сколько страниц всего в индексе:
Сейчас у меня в индексе всего «About 1,660 results». Выходит у меня 1660-558=1102 страниц в дополнительном индексе. В основном индексе у меня 34% страниц. Честно говоря, это не такой уж и плохой результат. Если же у вас более 50% страниц в основном индексе, то это уже считается хорошим достижением.
Следующий вопрос конечно будет «А как мне посмотреть какие именно страницы в дополнительном индексе?». Тут уже не все так просто, раньше это можно было выяснить с помощью такого запроса:
То есть показать все страницы в индексе, за исключением страниц из основного индекса. Но сейчас такой запрос не работает.
Я догадался выйти из ситуации другим методом. Разобьем сайт на части и проверим в какой из этих частей больше всего страниц в сопливом индексе. Например если вы увлекаетесь тегами, то таких страниц в сопливом индексе должно быть достаточно много, так как там дублирующийся контент, а если еще страница с тегом указывает только на одну-две статьи, то этого контента раз-два и обчелся. Под страницей с тегами подразумеваю страницы с такими адресами: elims.org.ua/blog/tag/span/
Итак, запрос «site:elims.org.ua inurl:/blog/tag/» показал 254 результата, а запрос «site:elims.org.ua/& inurl:/blog/tag/» — 3 результата. Выходит 251 страница с тегами основного подблога «/blog/» находится в сопливом индексе. Теперь я знаю над чем можно поработать. По аналогии можно проинспектировать остальные части сайта.
Результаты эксперимента: AJAX
Результат проверки при скрытии посредством технологии AJAX показал, что не в одном из 5 случаев не Яндекс, ни Google не смогли распознать в данном контенте ссылок.
Как видит Google?

Рис. 12. Сохраненная копия в Google.
Видно, что Яндекс и Google воспринимают данный контент как обычный текст и не интерпретирует его как блок ссылок.
Дополнительно произведем поисков текстов ссылок в анкор-листе страниц акцепторов с помощью оператора «allinanchor».
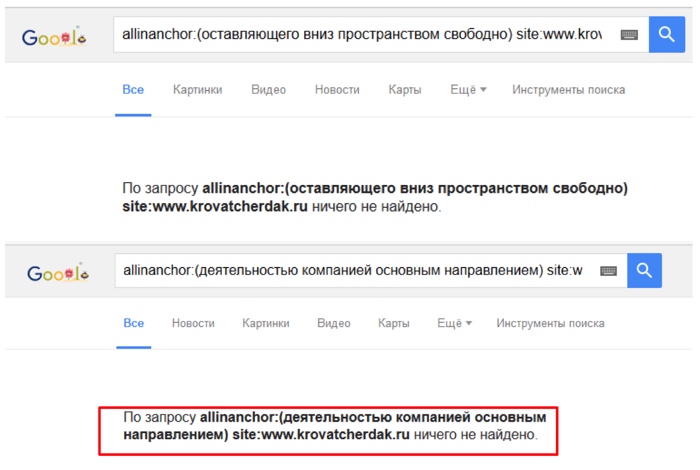
Рис. 13. Проверка наличия текстов ссылок в анкор-листе акцепторов.
В анкор-листе страниц акцепторов фразы из текстов ссылок не были найдены. Это является дополнительным подтверждением того, что поисковые системы не смогли проиндексировать ссылки, скрытые посредством AJAX.
Как проверить работу robots.txt
В Яндекс.Вебмастер (https://webmaster.yandex.ru/) есть инструмент для проверки конкретных адресов на разрешение или запрет их индексации в соответствии с файлом robots.txt вашего файла.
Для этого перейдите во вкладку Инструменты, выберите Анализ robots.txt. Этот файл должен загрузиться автоматически, если там старая версия, то нажмите кнопку Проверить:

Затем в поле Разрешены ли URL? введите адреса, которые вы хотите проверить. Можно за один раз вводить много адресов, каждый из них должен размещаться на новой строчке. Когда всё готово, нажмите кнопку Проверить.
В столбце Результат если URL адрес закрыт для индексации поисковыми роботами, он будет помечен красным светом, если открыт – то зелёным.

В Search Console (адрес https://www.google.com/webmasters/tools/robots-testing-tool) имеется аналогичный инструмент. Он находится во вкладке Сканирование. Называется Инструмент проверки файла robots.txt.
Если вы обновили файл robots.txt, то нажмите на кнопку Отправить, а затем в открывшемся окно снова на кнопку Отправить:

После этого перезагрузите страницу (клавиша F5):

Введите адрес для проверки, выберите бота и нажмите кнопку Проверить:

Блокировка доступа поисковым системам с помощью mod_rewrite
На самом деле, всё, что было описано выше, НЕ ГАРАНТИРУЕТ, что поисковые системы и запрещённые роботы не будут заходить и индексировать ваш сайт. Есть роботы, которые «уважают» файл robots.txt, а есть те, которые его просто игнорируют.
С помощью mod_rewrite можно закрыть доступ для определённых ботов
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} Google
RewriteCond %{HTTP_USER_AGENT} Yandex
RewriteRule ^ -
Приведённые директивы заблокируют доступ роботам Google и Yandex для всего сайта.
Если, допустим, нужно закрыть для индексирования только одну папку report/, то следующие директивы полностью закроют доступ к этой папке (будет выдаваться код ответа 403 Доступ Запрещён) для сканеров Google и Yandex.
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} Google
RewriteCond %{HTTP_USER_AGENT} Yandex
RewriteRule ^report/ -
Пять вариантов закрыть дубли на сайте от индексации Яндекс и Google
1 Вариант — и самый правильный, чтобы их не было — нужно физически от них избавиться т.е при любой ситуации кроме оригинальной страницы — должна показываться 404 ответ сервера
2 Вариант — использовать Атрибут rel=»canonical» — он и является самым верным. Так как помимо того, что не позволяет индексироваться дублям, так еще и передает вес с дублей на оригиналы
Ну странице дубля к коде необходимо указать
<link rel="canonical" href="http://www.examplesite.ru/url originalnoi stranicu"/>

3 Вариант избавиться от индексации дублей — это все дублирующие страницы склеить с оригиналами 301 редиректом через файл .htaccess
4 Вариант — метатеги на каждой странице дублей
5 Вариант — все тот же robots
Может пригодиться: продвижение сайта по трафику в Москве — готовы ли вы к приливу посетителей?
Операторы в robots.txt
Прежде, чем мы перейдём к обзору директив, ознакомимся с дополнительными операторами. Про символ # мы поговорили выше. Кроме него вам могут потребоваться следующие операторы:
«*» сообщает, что допускается любое число символов или таковые отсутствуют;
«$» поясняет, что находящийся перед ним символ является последним.
Директива User-agent
Адресует ваши команды определённому боту-поисковику. Именно с неё вы начинаете прописывать robots.txt.
(правила задаются для всех роботов Яндекса)
(правила задаются для всех роботов Google)
(правила задаются для всех поисковых систем)
Обращаю ваше внимание: когда поисковой робот обнаруживает своё имя после User-agent, то он не воспринимает все команды, которые вы зададите в блоке User-agent: *. И ещё, у отдельных поисковых систем существует целая группа ботов, команды для которых можно задавать в индивидуальном порядке
При этом блоки с рекомендациями для таких ботов разбиваются путём оставления пустой строки
И ещё, у отдельных поисковых систем существует целая группа ботов, команды для которых можно задавать в индивидуальном порядке. При этом блоки с рекомендациями для таких ботов разбиваются путём оставления пустой строки.
Поисковые роботы Google:
- Googlebot — основной бот системы;
- Googlebot-Image — обрабатывает изображения;
- Googlebot-Video — отслеживает видео-контент;
- Googlebot-Mobile — работает со страницами для мобильных девайсов;
- Adsbot-Google — анализирует качество рекламы на веб-страницах для персональных компьютеров;
- Googlebot-News — определяет веб-страницы, которые следует внести в Новости Google.
Поисковые роботы Yandex:
- YandexBot — основной бот системы;
- YandexImages — обрабатывает изображения;
- YandexNews — определяет веб-страницы для добавления в Яндекс.Новости;
- YandexMedia — отслеживает мультимедиа контент;
- YandexMobileBot — работает со страницами для мобильных девайсов.
Директива Disallow
Самая популярная команда — выдаёт запрет на индексацию страниц.
Примеры:
(закрытие доступа ко всему веб-ресурсу)
(закрытие доступа к панели администратора)
(закрытие доступа на обработку документов заданного типа)
Директива Allow
Даёт право обрабатывать поисковикам заданные вами веб-страницы. Это особенно актуально в процессе ведения техработ на сайте.
Например, вы модернизируете веб-ресурс, но каталог с товарами не подлежит изменениям. Вы закрываете доступ к своему сайту, а ботов направляете только к нужному вам разделу.
Пример:
Директива Host
До недавнего времени применялась для показа роботам Яндекса основного зеркала веб-сайта — с www или без.
Весной 2018 г. российская ИТ-компания проинформировала пользователей, что директива заменяется на редирект 301 — универсальный метод для всех работающих поисковиков, который указывает на основной сайт.
На сегодняшний день эта команда бесполезна. Но если она проставлена в файле, то ничего страшного — поисковые боты её просто игнорируют.
Директива Sitemap
Предназначена для указания пути к Карте вашего ресурса. По-хорошему, sitemap.xml должен храниться в корне веб-сайта. В случае, когда путь отличается, эта команда позволяет найти поисковикам Карту.
Директива Clean-param
Её задача — пояснить боту, что нет необходимости в индексировании страницы с определёнными параметрами. Это относится к динамическим ссылкам, ведь они периодически формируются в ходе работы веб-сайта и образуют дубли — то есть одинаковая страница становится доступна на нескольких адресах.
Тогда применяется «ref» — параметр, позволяющий выявить источник ссылки.
Пример:
Результат:
Таким образом поисковик сведёт все URL к одной странице. Она будет участвовать в поисковой выдаче при условии её наличия на веб-сайте:
Директива Crawl-Delay
Команда предназначена, чтобы уведомить бота-поисковика о продолжительности загрузки страницы (в секундах). Она позволяет снизить нагрузку на веб-ресурс. Это актуально, когда веб-сайт размещён на слабом сервере.
Выглядит это так:
(вы уведомили поисковика, что можно скачивать данные каждые 3.5 секунд)
Запрет индексации страницы или раздела
Теперь давайте разберем случай, если нужно запретить индексировать целую страницу. Делается это несколькими способами, выбирайте тот, который считаете удобнее.
С помощью robots.txt
Открываем файл и добавляем в него следующую строку:
Disallow: /address
Здесь вместо address вам нужно добавить url-адрес вашей страницы (без начала – http://great-world.ru/address). Аналогичным образом запрещается индексация разделов, просто добавьте вместо address название категории.
С помощью метатегов
В этом случае мы будем использовать метатег robots, который позволяет указать, можно ли индексировать страницу или нельзя. Воспринимается метатег всеми поисковыми системами. Добавлять строчки кода нужно в исходный html-код страницы между тегами <head></head>. Вот синтаксис записи:
<meta name=»robots» content=»noindex, nofollow»>
В приведенном выше примере страница запрещена для индексирования. Атрибут content может принимать такие значения:
- index – разрешается индексация страницы;
- noindex – запрещается индексация страницы;
- follow – разрешается индексация всех ссылок;
- nofollow – запрещается индексация всех ссылок;
- all – разрешается индексация ссылок и страницы;
- none – запрещается индексация ссылок и страницы
Как закрыть сайт от индексации с помощью мета-тэга
Служебный файл robots.txt, хранящийся в корневом каталоге сайта, позволяет влиять на весь ресурс. Инструментом точечного воздействия является мета-тег robots, разрешающий «спрятать» конкретную страницу ресурса (параметр index) и имеющиеся на ней ссылки (параметр follow). Специалисты отмечают, что Google отдает приоритет именно мета-тегу, считая его запреты и разрешения более авторитетными, чем прописанные в robots.txt.
Мета-тег robots вписывается внутрь HEAD перед <title>.

Параметры index и follow при запрете индексирования предваряет английское «нет» — no, прочитав которое добропорядочные роботы перейдут к следующим страницам, а вот для «воришек» установленные правила законом не являются. С ними нужно бороться другими способами, и это тема отдельной статьи. Пока же задача сводится к грамотному запрещению индексации честным поисковым ботам.
Закрыть страницу и имеющиеся на ней ссылки можно, вписав в код страницы:
<meta name=“robots” content=“noindex,nofollow”>.
Запретить паукам изучать ссылочную массу, оставив саму страницу видимой:
<metaname=“robots” content=“index,nofollow”>.
Ссылки остаются доступными, а страница скрывается от индексирования:
<meta name=“robots” content=“noindex,follow”>.
Эффективнее всего использовать оба инструмента: содружество robots.txt и мета-тега robots позволяет минимизировать риск проведения нежелательного индексирования и указать роботам путь, что существенно ускорит появление ресурса в поисковой базе данных.
Как в Битрикс закрыть сайт от индексации
Для этого нужно использовать метатег <meta name=»robots» content=»noindex, nofollow»>. Для скрытия какой-либо страницы от индексирования нужно, добавляя или изменяя условия, выбрать пункт «Закрыть от индексации».

Кроме того, возможно отключение индексации всех страниц с подключенным компонентом sotbit:seo.meta. Для этого нужно зайти в общие настройки модуля SEO умного фильтра и включить опцию «Отключить индексацию всех страниц».
Приоритетными будут настройки индексации в условии, а не эта опция. То есть в случае отключения в настройках условия опции «Закрыть от индексации» страница, удовлетворяющая этому условию, будет проиндексирована.
Закрытие от индексации элементов на страницах сайта
SEO-тег <noindex>
SEO-тег <noindex> не используется в официальной спецификации html, и был придуман Яндексом как альтернатива атрибуту nofollow. Пример корректного использования данного тега:
<!—noindex—>Любая часть страницы сайта: код, текст, который нужно закрыть от индексации<!—/noindex—>
Примеры использования тега <noindex> для закрытия от индексации элементов на страницах сайта:
- нужно скрыть коды счетчиков (liveinternet, тИЦ и прочих служебных);
- запрятать неуникальный или дублирующийся контент (copypast, цитаты и пр.);
- спрятать от индексации динамичный контент (например, контент, который выдается в зависимости от того, с какими параметрами пользователь зашел на сайт);
- чтоб хотя бы минимально обезопасить себя от спам-ботов, необходимо закрывать от индексации формы подписки на рассылку;
- закрыть информацию в сайдбаре (например, рекламный баннер, текстовую информацию, как это сделала Розетка).

Атрибут rel=»nofollow»
Если к ссылке добавить атрибут rel=»nofollow», тогда все поисковые системы, которые поддерживают стандарты Консорциума Всемирной паутины (а к ним относятся и Яндекс и Google) не будут учитывать вес ссылки при расчете индекса цитирования сайта.
Примеры использования атрибута rel=»nofollow» тега <a>:
- поощрение и наказание комментаторов вашего сайта. Т.е. спамерские ссылки в комментариях либо можно удалять, либо закрывать в nofollow (если ссылка тематична, но вы не уверены в ее качестве);
- рекламные ссылки или ссылки, размещенные «по бартеру» (обмен постовыми);
- не передавать вес очень популярному ресурсу, типа Википедии, Одноклассников и пр.;
- приоритезация сканирования поисковыми системами. Лучше закрыть от перехода по ссылкам для ботов Ваши формы регистрации.
SEOhide
Спорная технология, в сути которой с помощью javacript скрывать от поисковиков ненужный с точки зрения SEO-специалиста контент. А это «попахивает» клоакингом, когда пользователи видят одно, а поисковики – другое. Но давайте посмотрим на плючсы и минусы данной технологии:
Плюсы:
+ корректное управление статическим и анкорным весом;
+ борьба с переспамом (уменьшение количества ключевых слов на странице, так называемый показатель «тошноты» текста);
+ можно использовать для всех поисковых систем без ограничений, как в случае с noindex;
Минусы:
— вскоре поисковые системы научатся индексировать JS;
— в данный момент данная технология может быть воспринята поисковиками как клоакинг.
Подробнее об этой технологи смотрите в видео:
https://youtube.com/watch?v=ULUajs3bgN8
Внутренние ссылки
Внутренние ссылки закрываются от индексации для перераспределения внутренних весов на основные продвигаемые страницы. Но дело в том, что:
– такое перераспределение может плохо отразиться на общих связях между страницами;
– ссылки из шаблонных сквозных блоков обычно имеют меньший вес или могут вообще не учитываться.
Рассмотрим варианты, которые используются для скрытия ссылок:
Для скрытия ссылок этот тег бесполезен. Он распространяется только на текст.
Атрибут rel=”nofollow”
Сейчас атрибут не позволяет сохранять вес на странице. При использовании rel=”nofollow” вес просто теряется. Само по себе использование тега для внутренних ссылок выглядит не особо логично.
Представители Google рекомендуют отказаться от такой практики.
Рекомендацию Рэнда Фишкина:

Скрытие ссылок с помощью скриптов
Это фактически единственный рабочий метод, с помощью которого можно спрятать ссылки от поисковых систем. Можно использовать Аjax и подгружать блоки ссылок уже после загрузки страницы или добавлять ссылки, подменяя скриптом тег на
При этом важно учитывать, что поисковые алгоритмы умеют распознавать скрипты
Как и в случае с контентом – это «костыль», который иногда может решить проблему. Если вы не уверены, что получите положительный эффект от спрятанного блока ссылок, лучше такие методы не использовать.
Как закрыть внешние, исходящие ссылки от индексации на WordPress
Сделать закрытыми внешние ссылки от поисковых ботов можно, используя несколько тегов и плагинов, которые легко установить на платформе Word Press. На сегодняшний день существуют следующие способы:
- использование конструкции rel=”nofollow”;
- использование ряда плагинов;
- применение тега “noindex”;
- подключение AJAX – наиболее современный метод, и он же самый оптимальный вариант.
Каждый из методов обладает достаточными
преимуществами практического применения, но выделяют более современные способы,
вытесняющие устаревшие теги. К сожалению, скрипты Java более не приносят ожидаемого эффекта, так как содержимое скрипта на сегодняшний
день также читается поисковым ботом.
Используемые директивы
User-agent
Все блоки правил начинаются с директивы User-agent, в которой указывается название робота, для которого задается правило. Запись вида User-agent: * означает, что правило задается для всех поисковых роботов.
Например, при следующей записи правило будет применено только к основному индексирующему боту Яндекса:
User-agent: YandexBot
Правило будет применено ко всем роботам Яндекса и Google:
User-agent: Yandex User-agent: Googlebot
Правило будет применено вообще ко всем роботам:
User-agent: *
Disallow и Allow
Директивы используются, чтобы запретить и разрешить доступ к определенным разделам сайта.
Например, можно запретить индексацию всего сайта (Disallow: /), кроме определенного каталога (Allow: /catalog):
User-agent: имя_бота Disallow: / Allow: /catalog
Запретить индексацию страниц, начинающихся с /catalog, но разрешить для страниц, начинающихся с /catalog/auto и /catalog/new:
User-agent: имя_бота Disallow: /catalog Allow: /catalog/auto Allow: /catalog/new
В каждой строке указывается только одна директория. Для запрещения (или разрешения) доступа к нескольким каталогам, для каждого требуется отдельная запись.
С помощью Disallow можно ограничить доступ к сайту для нежелательных ботов, тем самым снизив создаваемую ими нагрузку. Например, чтобы запретить доступ ко всему сайту для MJ12bot и AhrefsBot — ботов сервиса majestic.com и ahrefs.com — используйте:
User-agent: MJ12bot User-agent: AhrefsBot Disallow: /
Аналогичным образом устанавливается блокировка и для других ботов (скажем, DotBot, SemrushBot и других).
Примечания:
- Пустая директива Disallow: равнозначна Allow: /, то есть «не запрещать ничего».
- В директивах может использоваться символ $ для обозначения точного соответствия указанному параметру. Например, запись Disallow: /catalog аналогична Disallow: /catalog * и запретит доступ ко всем страницам с /catalog (/catalog, /catalog1, /catalog-new, /catalog/clothes и др.).Использование $ это изменит. Disallow: /catalog$ запретит доступ к /catalog, но разрешит /catalog1, /catalog-new, /catalog/clothes и др.
Sitemap
При использовании файла sitemap.xml для описания структуры сайта, можно указать путь к нему с помощью соответствующей директивы:
User-agent: * Disallow: Sitemap: https://mydomain.com/путь_к_файлу/mysitemap.xml
Можно перечислить несколько файлов Sitemap, каждый в отдельной строке.
Host
Директива используется для указания роботам Яндекса основного зеркала сайта и полезна, когда сайт доступен по нескольким доменам.
User-agent: Yandex Disallow: /catalog1$ Host: https://mydomain.com
Примечания:
- Директива Host может быть только одна; если в файле указано несколько, роботом будет учтена только первая.
- Необходимо указывать протокол https, если он используется. Если вы используете http, зеркало можно записать в виде mydomain.com
- Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Crawl-delay
Директива устанавливает минимальный интервал в секундах между обращениями робота к сайту, что может быть полезно для снижения создаваемой роботами нагрузки. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами (разделитель — точка).
User-agent: Yandex Disallow: Crawl-delay: 0.5
Примечания:
- Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Clean-param
Директива используется для робота Яндекса. Она позволяет исключить из индексации страницы с динамическими параметрами в URL-адресах (это могут быть идентификаторы сессий, пользователей, рефереров), чтобы робот не индексировал одно и то же содержимое повторно, повышая тем самым нагрузку на сервер.
Например, на сайте есть страницы:
www.mydomain.ru/news.html?&parm1=1&parm2=2 www.mydomain.ru/news.html?&parm2=2&parm3=3
По факту по обоим адресам отдается одна и та же страница — www.mydomain.ru/news.html, при этом в URL присутствуют дополнительные динамические параметры.
Чтобы робот не индексировал каждую подобную страницу, можно использовать директиву:
User-agent: Yandex Disallow: Clean-param: parm1&parm2&parm3 /news.html
Через знак & указываются параметры, которые робот должен игнорировать. Далее указывается страница, для которой применяется данное правило