Продвинутое использование robots.txt без ошибок
Содержание:
- Используемые директивы
- Для чего нужен файл robots.txt
- Настройка через хостинг и плагин
- Как проверить файл robots.txt
- Для чего нужен robots.txt
- Плагины для редактирования robots.txt
- Создание robots.txt для WordPress , Joomla и Ucoz
- Robots.txt для Яндекса и Google
- Что такое файл robots.txt?
- Как создать правильный файл Robots.txt для сайта
- Заключение
Используемые директивы
User-agent
Все блоки правил начинаются с директивы User-agent, в которой указывается название робота, для которого задается правило. Запись вида User-agent: * означает, что правило задается для всех поисковых роботов.
Например, при следующей записи правило будет применено только к основному индексирующему боту Яндекса:
User-agent: YandexBot
Правило будет применено ко всем роботам Яндекса и Google:
User-agent: Yandex User-agent: Googlebot
Правило будет применено вообще ко всем роботам:
User-agent: *
Disallow и Allow
Директивы используются, чтобы запретить и разрешить доступ к определенным разделам сайта.
Например, можно запретить индексацию всего сайта (Disallow: /), кроме определенного каталога (Allow: /catalog):
User-agent: имя_бота Disallow: / Allow: /catalog
Запретить индексацию страниц, начинающихся с /catalog, но разрешить для страниц, начинающихся с /catalog/auto и /catalog/new:
User-agent: имя_бота Disallow: /catalog Allow: /catalog/auto Allow: /catalog/new
В каждой строке указывается только одна директория. Для запрещения (или разрешения) доступа к нескольким каталогам, для каждого требуется отдельная запись.
С помощью Disallow можно ограничить доступ к сайту для нежелательных ботов, тем самым снизив создаваемую ими нагрузку. Например, чтобы запретить доступ ко всему сайту для MJ12bot и AhrefsBot — ботов сервиса majestic.com и ahrefs.com — используйте:
User-agent: MJ12bot User-agent: AhrefsBot Disallow: /
Аналогичным образом устанавливается блокировка и для других ботов (скажем, DotBot, SemrushBot и других).
Примечания:
- Пустая директива Disallow: равнозначна Allow: /, то есть «не запрещать ничего».
- В директивах может использоваться символ $ для обозначения точного соответствия указанному параметру. Например, запись Disallow: /catalog аналогична Disallow: /catalog * и запретит доступ ко всем страницам с /catalog (/catalog, /catalog1, /catalog-new, /catalog/clothes и др.).Использование $ это изменит. Disallow: /catalog$ запретит доступ к /catalog, но разрешит /catalog1, /catalog-new, /catalog/clothes и др.
Sitemap
При использовании файла sitemap.xml для описания структуры сайта, можно указать путь к нему с помощью соответствующей директивы:
User-agent: * Disallow: Sitemap: https://mydomain.com/путь_к_файлу/mysitemap.xml
Можно перечислить несколько файлов Sitemap, каждый в отдельной строке.
Host
Директива используется для указания роботам Яндекса основного зеркала сайта и полезна, когда сайт доступен по нескольким доменам.
User-agent: Yandex Disallow: /catalog1$ Host: https://mydomain.com
Примечания:
- Директива Host может быть только одна; если в файле указано несколько, роботом будет учтена только первая.
- Необходимо указывать протокол https, если он используется. Если вы используете http, зеркало можно записать в виде mydomain.com
- Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Crawl-delay
Директива устанавливает минимальный интервал в секундах между обращениями робота к сайту, что может быть полезно для снижения создаваемой роботами нагрузки. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами (разделитель — точка).
User-agent: Yandex Disallow: Crawl-delay: 0.5
Примечания:
- Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Clean-param
Директива используется для робота Яндекса. Она позволяет исключить из индексации страницы с динамическими параметрами в URL-адресах (это могут быть идентификаторы сессий, пользователей, рефереров), чтобы робот не индексировал одно и то же содержимое повторно, повышая тем самым нагрузку на сервер.
Например, на сайте есть страницы:
www.mydomain.ru/news.html?&parm1=1&parm2=2 www.mydomain.ru/news.html?&parm2=2&parm3=3
По факту по обоим адресам отдается одна и та же страница — www.mydomain.ru/news.html, при этом в URL присутствуют дополнительные динамические параметры.
Чтобы робот не индексировал каждую подобную страницу, можно использовать директиву:
User-agent: Yandex Disallow: Clean-param: parm1&parm2&parm3 /news.html
Через знак & указываются параметры, которые робот должен игнорировать. Далее указывается страница, для которой применяется данное правило
Для чего нужен файл robots.txt
Этот файл содержит ряд рекомендаций, адресованных поисковым ботам. Он ограничивает их доступ к некоторым частям сайта. Из-за размещения этого файла в корневом каталоге, боты никак не смогут его пропустить. В результате, попадая на ваш ресурс, они сначала читают правила его обработки, а уже только после этого начинают проверку.
Таким образом, файл указывает поисковым роботам, какие директории сайта разрешены для индексирования, и какие этому процессу не подлежат.

Учитывая, что на процесс ранжирования наличие файла напрямую не влияет, много сайтов не содержат robots.txt. Но путь полного доступа нельзя считать техически правильным. Рассмотрим преимущества robots.txt, которые он дает ресурсу.
Можно запретить индексирование ресурса целиком или частично, ограничить круг поисковых роботов, которые будут иметь право на проведение индексирования. Приказывая robots.txt запретить все, вы сможете полностью изолировать ресурс на время ремонта или реконструкции.
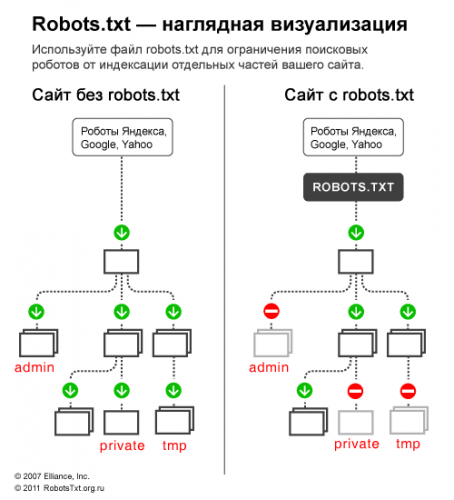 Кроме того, файл роботс ограничивает доступ на ресурс всевозможных спам-роботов. Их основная цель — сканирование сайта на наличие электронных адресов, которые потом будут использоваться для рассылки спама. Не будем останавливаться на том, к чему это может привести — и так понятно.
Кроме того, файл роботс ограничивает доступ на ресурс всевозможных спам-роботов. Их основная цель — сканирование сайта на наличие электронных адресов, которые потом будут использоваться для рассылки спама. Не будем останавливаться на том, к чему это может привести — и так понятно.
От индексирования можно скрыть разделы сайта, предназначенные не для поисковых машин, а для определенного круга пользователей, разделы, содержащие приватную и прочую подобную информацию.
Настройка через хостинг и плагин
Если вы создаете файл самостоятельно, то для работы с ним рекомендуется использовать текстовый редактор, который не добавляет лишний код в разметку, например, Notepad++.
Основные директивы, которые понадобятся в настройке robots.txt через хостинг или плагин, например, Yoast SEO — выглядят следующим образом:
- User-agent: — указывает к каким поисковым роботам применяется правило, например, Yandex, * (роботы всех ПС), Googlebot;
- Disallow: — запрещает индексацию;
- Allow: — индексация разрешена;
- Sitemap: — указывает на расположение файла sitemap.xml. В данном файле содержатся все страницы, предназначенные для индексирования;
- Host: — указывает на главное зеркало сайта, например, https://домен.ru/. В данный момент, директива Host не используется и прописывать ее в файле robots.txt — не надо.
Как запретить индексирование сайта в robots.txt
Чтобы запретить индексирование сайта в robots.txt для всех поисковых роботов, используйте следующую конструкцию:
User-agent: * Disallow: /
robots для блога/сайта на WordPress
Файл robots.txt для WordPress выглядит следующим образом:
User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /tag Disallow: /*?* Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg Sitemap: https://заменить на домен вашего сайта/sitemap.xml (если не используете плагин Yoast SEO) Sitemap: https://заменить на домен вашего сайта/sitemap_index.xml (если используете плагин Yoast SEO)
Для WooCommerce
Файл robots.txt для WooCommerce выглядит следующим образом:
User-agent: * Disallow: /cgi-bin Disallow: /wp- Disallow: /tag Disallow: /wp-admin Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: *?replytocom Disallow: *?* Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Disallow: /my-account/ Disallow: /wp-login.php Disallow: /wp-register.php Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /tag Disallow: *?replytocom Disallow: *?* Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Disallow: /my-account/ Disallow: /wp-login.php Disallow: /wp-register.php Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg Sitemap: https://заменить на домен вашего сайта/sitemap.xml (если не используете плагин Yoast SEO) Sitemap: https://заменить на домен вашего сайта/sitemap_index.xml (если используете плагин Yoast SEO)
Готовый файл robots.txt загрузите на хостинг, в корень сайта или создайте его там через стандартный менеджер файлов и сохраните изменения.
Повторюсь, если редактируете robots.txt на компьютере или работаете с любым другим файлом, который содержит в себе код, то используйте для этого Notepad++.
Для примера, этот текст написан в OpenOffice и если его скопировать и вставить, например, в онлайн HTML-редактор, то увидите это:

Некоторые редакторы автоматически добавляют теги разметки в текст, а чтобы этого не происходило — используйте предназначенные для этого инструменты.
Настройка через плагин Yoast SEO
Если у вас установлен плагин Yoast SEO, то для создания и редактирования файла robots.txt в нем предусмотрена эта функция.
Для того,чтобы создать или редактировать — перейдите в настройки «SEO» и выберите пункт «Инструменты».

Если файла нет, то плагин предложит создать его.

Для этого нажмите на соответствующую кнопку «Создать файл robots.txt». В поле ниже автоматически появятся следующие строки:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php

Если вы хотите запретить поисковым роботам индексировать сайт на момент разработки, то измените содержимое на:
User-agent: * Disallow: /
Если вы готовы запустить проект, то настройте содержимое файла через редактор плагина.
Не забудьте сохранить настройки.
Как проверить файл robots.txt
После того, как файл написан, нужно узнать, правильно ли. Для этого вы можете использовать инструменты от Яндекс и Google.
Через Яндекс.Вебмастер robots.txt можно проверить на вкладке «Инструменты – Анализ robots.txt»:
На открывшейся странице указываем адрес проверяемого сайта, а в поле снизу вставляем содержимое своего файла. Затем нажимаем «Проверить». Сервис проверит ваш файл и укажет на возможные ошибки:

Также можно проверить файл robots.txt через Google Search Console, если у вас подтверждены права на сайт.
Для этого в панели инструментов выбираем «Сканирование – Инструмент проверки файла robots.txt».
На странице проверки вам тоже нужно будет скопировать и вставить содержимое файла, затем указать адрес сайта:

Потом нажимаете «Проверить» — и все. Система укажет ошибки или выдаст предупреждения.
Останется только внести необходимые правки.
Если в файле присутствуют какие-то ошибки, или появятся со временем (например, после какого-то очередного изменения), инструменты для вебмастеров будут присылать вам уведомления об этом. Извещение вы увидите сразу, как войдете в консоль.
Это интересно: 20 самых распространённых ошибок, которые убивают ваш сайт
Для чего нужен robots.txt
Файл robots.txt создается для настройки правильной индексации сайта поисковым системам. То есть в нем содержатся правила разрешений и запретов на определенные пути вашего сайта или тип контента. Но это не панацея. Все правила в файле robots не являются указаниями точно им следовать, а просто рекомендация для поисковых систем. Google например пишет:
Поисковые роботы сами решают что индексировать, а что нет, и как себя вести на сайте. У каждого поисковика свои задачи и свои функции. Как бы мы не хотели, этим способ их не укротить.
Но есть один трюк, который не касается напрямую тематики этой статьи. Чтобы полностью запретить роботам индексировать и показывать страницу в поисковой выдаче, нужно написать:
<meta name="robots" content="noindex" />
Вернемся к robots. Правилами в этой файле можно закрыть или разрешить доступ к следующим типам файлов:
- Неграфические файлы. В основном это html файлы, на которых содержится какая-либо информация. Вы можете закрыть дубликаты страниц, или страницы, которые не несут никакой полезной информации (страницы пагинации, страницы календаря, страницы с архивами, страницы с профилями и т.д.).
- Графические файлы. Если вы хотите, чтобы картинки сайта не отображались в поиске, вы можете это прописать в файле robots.
- Файлы ресурсов. Также с помощью robots вы можете заблокировать индексацию различных скриптов, файлы стилей CSS и другие маловажные ресурсы. Но не стоит блокировать ресурсы, которые отвечают за визуальную часть сайта для посетителей (например, если вы закроете css и js сайта, которые выводят красивые блоки или таблицы, этого не увидит поисковой робот, и будет ругаться на это).
Чтобы наглядно показать, как работает robots, посмотрите на картинку ниже:
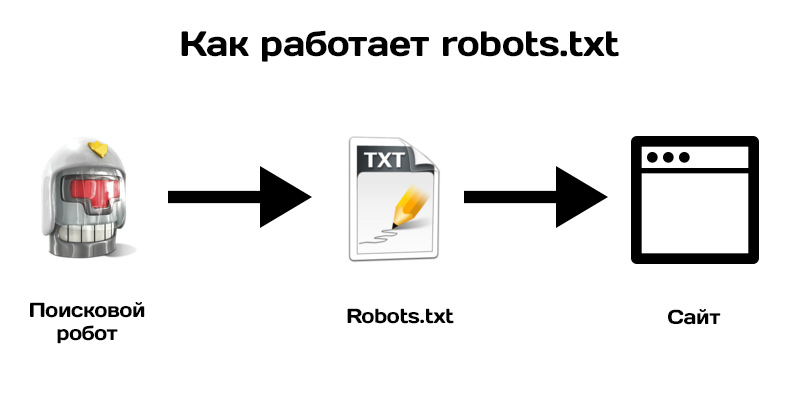
Поисковой робот, следуя на сайт, смотрит на правила индексации, затем начинает индексацию по рекомендациям файла.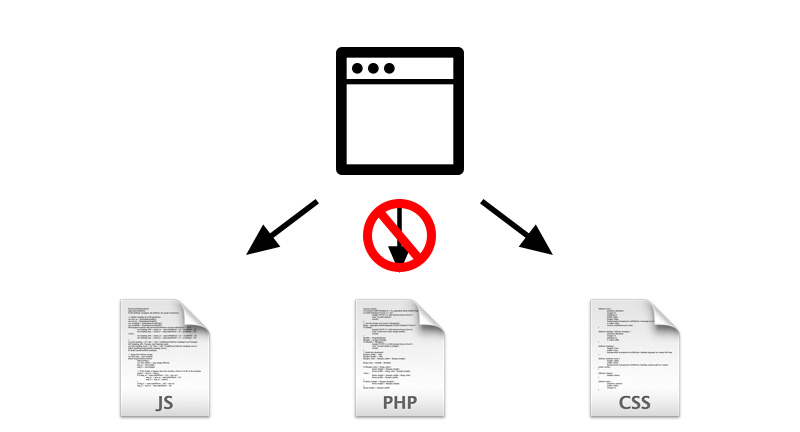
В зависимости от настроек правил, поисковик знает, что можно индексировать, а что нет.
Плагины для редактирования robots.txt
Гораздо проще внести нужные директивы в robots.txt с помощью специальных плагинов для редактирования прямо из панели управления WordPress. Самые популярные из них — ClearfyPro, Yoast SEO и All in One SEO Pack.
Clearfy Pro
Этот плагин отлично подходит для начинающих: даже если вы ничего не понимаете в SEO, Clearfy сам создаст правильный и валидный файл robots.txt. Кроме этого, плагин предлагает пошаговую настройку самых важных для поисковой оптимизации функций, так что на первых этапах развития сайта этого будет достаточно.
Чтобы настроить robots.txt, в панели управления WordPress перейдите в пункт Настройки ⟶ Clearfy ⟶ SEO.

Переключите «Создайте правильный robots.txt» в положение «Вкл». Clearfy отобразит правильные настройки файла robots.txt. Вы можете дополнить эти настройки, например, запретив поисковым роботам индексировать папку /wp-admin/.
После внесения настроек нажмите на кнопку «Сохранить» в верхнем правом углу.
Yoast SEO
Плагин Yoast SEO хорош тем, что в нем есть много настроек для поисковой оптимизации: он напоминает использовать ключевые слова на странице, помогает настроить шаблоны мета-тегов и предлагает использовать мета-теги Open Graph для социальных сетей.
С его помощью можно отредактировать и robots.txt.
Для этого зайдите в раздел Yoast SEO ⟶ Инструменты ⟶ Редактор файлов.

Здесь вы сможете отредактировать robots.txt и сохранить его, не заходя на хостинг. По умолчанию Yoast SEO не предлагает никаких настроек для файла, так что его придется прописать вручную.

После изменений нажмите на кнопку «Сохранить изменения в robots.txt».
All in One SEO Pack
Еще один мощный плагин для управления SEO на WordPress. Чтобы отредактировать robots.txt через All in One SEO Pack, сначала придется активировать специальный модуль. Для этого перейдите на страницу плагина в раздел «Модули» и нажмите «Активировать» на модуле «robots.txt».

После подключения модуля перейдите на его страницу. С помощью него можно разрешать или запрещать для обработки конкретные страницы и группы страниц для разных поисковых роботов, не прописывая директивы вручную.

Создание robots.txt для WordPress , Joomla и Ucoz
Различные CMS, получившие широкую популярность на просторах Рунета, предлагают пользователям свои версии файлов robots.txt. Некоторые из них не имеют таких файлов вовсе. Зачастую эти файлы либо слишком универсальны и не учитывают особенностей ресурса пользователя, либо имеют ряд существенных недостатков.
Опытный специалист может вручную исправить положение (при недостатке знаний так лучше не делать). Если вы боитесь копаться во внутренностях сайта, воспользуйтесь услугами коллег. Подобные манипуляции, при знании дела, занимают всего пару минут времени. Например, robots.txt WordPress может выглядеть таким образом:
 Файл robots.txt для Ucoz предоставляется автоматически. Он имеет оптимальные настройки. Единственный его недостаток — система создаст файл, спустя примерно месяц, после конструирования ресурса. Если неохота ждать, можно написать файл самостоятельно. Выглядеть он будет так:
Файл robots.txt для Ucoz предоставляется автоматически. Он имеет оптимальные настройки. Единственный его недостаток — система создаст файл, спустя примерно месяц, после конструирования ресурса. Если неохота ждать, можно написать файл самостоятельно. Выглядеть он будет так:
 Joomla позволяет нескольким URL ссылаться на одну и ту же страницу. Поисковые системы примут такие настройки за дублирование контента. Избежать этого поможет установка robots.txt для Joomla следующего содержания:
Joomla позволяет нескольким URL ссылаться на одну и ту же страницу. Поисковые системы примут такие настройки за дублирование контента. Избежать этого поможет установка robots.txt для Joomla следующего содержания:

В последних двух строчках, как несложно догадаться, нужно прописать данные собственного ресурса.

Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt.
Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt», название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами —
http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает
стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
 Доступная для пользователей ссылка
Доступная для пользователей ссылка
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Что такое файл robots.txt?
Robots.txt это обычный текстовый файл, содержащий руководство для ботов поисковых систем (Яндекс, Google, etc.) по сканированию и индексации вашего сайта. Таким образом, каждый поисковый бот (краулер) при обходе страниц сайта сначала скачивает актуальную версию robots.txt (обновляет его содержимое в своем кэше), а затем, переходя по ссылкам на сайте, заносит в свой индекс только те страницы, которые разрешены к индексации в настройках данного файла.
|
User-agent: * Sitemap: https://somesite.com/sitemap.xml |
При этом у каждого краулера существует такое понятие, как «краулинговый бюджет», определяющее, сколько страниц можно просканировать единоразово (для разных сайтов это значение варьируется: обычно в зависимости от объема и значимости сайта). То есть, чем больше страниц на сайте и чем популярнее ресурс, тем объемнее и чаще будет идти его обход краулерами, и тем быстрее эти данные попадут в поисковую выдачу (например, на крупных новостных сайтах поисковые боты постоянно сканируют контент на предмет поиска новой информации (можно сказать что «живут»), за счет чего поисковая система может выдавать пользователем самые актуальные новости уже через несколько секунд после их публикации на сайте).
Таким образом, из-за ограниченности краулингового бюджета рекомендуется отдавать поисковым ботам в приоритете только ту информацию, которая должна обновляться или появляться в индексе поисковиков наиболее быстро (например, важные, полезные и актуальные страницы сайта), а все прочее устаревшее и не нужное можно смело скрывать, тем самым не распыляя краулинговый бюджет на не имеющий ценности контент.
Вывод: для оптимизации индексирования сайта стоит исключать из сканирования дубликаты страниц, результаты локального поиска по сайту, личный кабинет, корзину, сравнения, сортировки и фильтры, пользовательские профили, виш-листы и всё, что не имеет ценности для обычного пользователя.
Как создать правильный файл Robots.txt для сайта
Файл Robots.txt можно создать просто в программе «Блокнот», которая по умолчанию есть на любом компьютере. Прописывание файла займет даже у новичка максимум полчаса времени (если знать команды).
Также можно использовать другие программы – Notepad, например. Есть и онлайн сервисы, которые могут сгенерировать файл автоматически. Например, такие как CY-PR.com или Mediasova.
Вам просто нужно указать адрес своего сайта, для каких поисковых систем нужно задать правила, главное зеркало (с www или без). Дальше сервис всё сделает сам.
Лично я предпочитаю старый «дедовский» способ – прописать файл вручную в блокноте. Есть ещё и «ленивый способ» — озадачить этим своего разработчика Но даже в таком случае вы должны проверить, правильно ли там всё прописано. Поэтому давайте разберемся, как составить этот самый файл, и где он должен находиться.
Это интересно: Как увеличить посещаемость сайта
Где должен находиться файл Robots
Готовый файл Robots.txt должен находиться в корневой папке сайта. Просто файл, без папки:
Хотите проверить, есть ли он на вашем сайте? Вбейте в адресную строку адрес: site.ru/robots.txt. Вам откроется вот такая страничка (если файл есть):

Файл состоит из нескольких блоков, отделённых отступом. В каждом блоке – рекомендации для поисковых роботов разных поисковых систем (плюс блок с общими правилами для всех), и отдельный блок со ссылками на карту сайта – Sitemap.
Внутри блока с правилами для одного поискового робота отступы делать не нужно.
Каждый блок начинается директивой User-agent.
После каждой директивы ставится знак «:» (двоеточие), пробел, после которого указывается значение (например, какую страницу закрыть от индексации).
Нужно указывать относительные адреса страниц, а не абсолютные. Относительные – это без «www.site.ru». Например, вам нужно запретить к индексации страницу www.site.ru/shop. Значит после двоеточия ставим пробел, слэш и «shop»:
Disallow: /shop.
Звездочка (*) обозначает любой набор символов.
Знак доллара ($) – конец строки.
Вы можете решить – зачем писать файл с нуля, если его можно открыть на любом сайте и просто скопировать себе?
Для каждого сайта нужно прописывать уникальные правила. Нужно учесть особенности CMS. Например, та же админпанель находится по адресу /wp-admin на движке WordPress, на другом адрес будет отличаться. То же самое с адресами отдельных страниц, с картой сайта и прочим.
Заключение
Итак, в данной статье мы рассмотрели вопрос, что собой представляет файл robots txt, выяснили, что этот файл является очень важным для сайта. Узнали, как сделать правильный robots txt, как адаптировать файл robots txt с чужого сайта к себе, как закачать его на свой блог, как его проверить.
Из статьи стало понятно, что новичкам, на первых порах, лучше использовать готовый и правильный robots txt, но надо не забыть заменить в нем в директории Host домен на свой, а также прописать адрес своего блога в картах сайта. Скачать мой файл robots txt можно здесь. Теперь, после исправления, можете использовать файл на своем блоге.
Отдельно по файлу robots txt есть сайт Вы можете зайти на него и узнать более подробную информацию. Надеюсь, у Вас всё получится и блог будет хорошо индексироваться. Удачи Вам!
P.S. Для правильного продвижения блога надо правильно писать о оптимизировать статьи на блоге, тогда на нём будет высокая посещаемость и рейтинги. В этом Вам помогут мои инфопродукты, в которые вложен мой трёхлетний опыт. Можете получить следующие продукты:
- пошаговый алгоритм написания мощных статей для блога;
- платная книга Как написать статью для блога;
- интеллект карта Пошаговый алгоритм создания блога (сайта) для новичков;
- платный видео-курс «Как написать и оптимизировать статью для блога. Продвижение блога статьями«.
Просмотров: 12515