Семантическое ядро
Содержание:
- Бесплатный парсинг запросов конкурентов
- Как составить семантическое ядро
- Плюсы и минусы анализа семантического ядра конкурентов с помощью специальных сервисов
- Для чего нужно семантическое ядро
- Автоматический сбор семантического ядра онлайн
- Что такое семантическое ядро простыми словами
- Wordstat Яндекса и расширения для браузера
- Этапы работы с семантическим ядром
- Оценка стоимости продвижения запроса
- Что такое кластеризация семантического ядра
Бесплатный парсинг запросов конкурентов
Чтобы парсить конкурентов, их надо знать. В анализе ниш я уже рассказывал, как определить своих конкурентов.
Выписываем всех ваших конкурентов, если вы еще этого не сделали. Надо брать только прям точных конкурентов. Например, у вас сайт по диабету, вам надо брать только сайты по диабету. Сайты, которые посвящены всей медицине с разделом диабета не подойдут, потому что у вас напарсятся другие разделы сайта, которые посвящены не диабету, и вы запаритесь их чистить.
Wizard.Sape
Заходите в KeyCollector во вкладку Wizard.Sape. Выбираем анализ доменов. Вводим логин, пароль. Любой тематический url и своих конкурентов списком. Нажимаем начать сбор.
Вводим логин, пароль. Любой тематический url и своих конкурентов списком. Нажимаем начать сбор.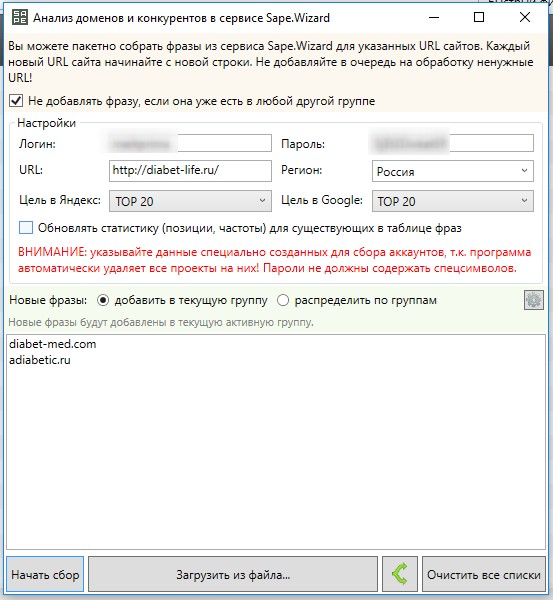 После сбора, в колонке частотность wordstat, появляются цифры сервиса их необходимо очистить.
После сбора, в колонке частотность wordstat, появляются цифры сервиса их необходимо очистить.
Так же можно еще собрать “сбор расширений ключевых фраз” в той же самой вкладке в KeyCollector.
Megaindex
Заходим в KeyCollector во вкладку Megaindex. Вводим логин и пароль, указываем Москва, потому что Россию нельзя указать. Выбираем последнюю дату, раньше можно было парсить за весь период, но сейчас почему-то не работает, можно выбирать только определенную дату. Вбиваем домены конкурентов. И начинаем парсинг.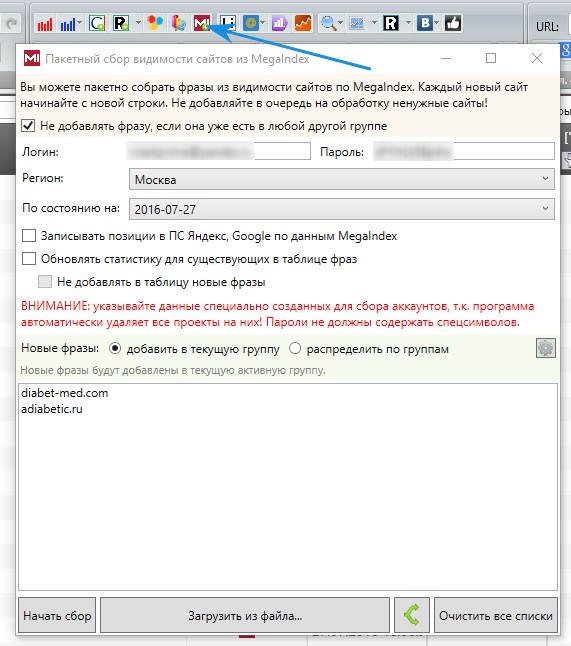
Rookee
Выбираем Rookee в Keycollector, составление семантического ядра.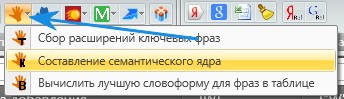 Здесь все проще, выбираем Москва, топ 10 и вводим конкурентов с http://
Здесь все проще, выбираем Москва, топ 10 и вводим конкурентов с http://
Можно отдельно собрать по Яндексу, потом по Гуглу. Так же можно собрать “сбор расширений ключевых фраз” в той же самой вкладке в KeyCollector.
Так же можно собрать “сбор расширений ключевых фраз” в той же самой вкладке в KeyCollector.
Top.Mail.ru
Здесь все сложнее. Необходимо перейти в рейтинг https://top.mail.ru/, и там найти ваших конкурентов с открытым счетчиком. Обычно что-то узконишевое там сложно найти, но все равно расскажу про этот способ для общего кругозора.
Вводим вашу тематику в поле поиска рейтинга.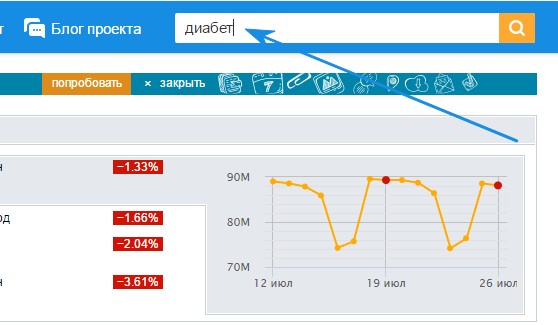 Получаем сайты. Как видим нашей тематики тут нет. Замочек напротив сайта – стата закрыта. Значок рейтинга – стата открыта.
Получаем сайты. Как видим нашей тематики тут нет. Замочек напротив сайта – стата закрыта. Значок рейтинга – стата открыта. Так вот, если бы мы делали сайт не по диабету, а по косметике, то первый сайт бы нам подошел. У него открыта стата и мы можем спарсить её. Переходим на него и смотрим его id.
Так вот, если бы мы делали сайт не по диабету, а по косметике, то первый сайт бы нам подошел. У него открыта стата и мы можем спарсить её. Переходим на него и смотрим его id. В KeyCollector щелкаем на значок mail, сбор статистики из счетчиков TOP.MailУказываем id счетчика и выставляем самый большой срок данных, 3 года.
В KeyCollector щелкаем на значок mail, сбор статистики из счетчиков TOP.MailУказываем id счетчика и выставляем самый большой срок данных, 3 года.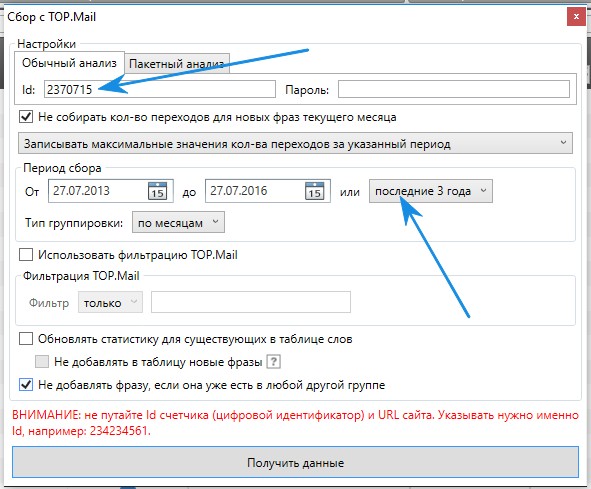 Есть так же пакетный анализ, где можно указывать сразу много счетчиков.
Есть так же пакетный анализ, где можно указывать сразу много счетчиков.
Так же можно спарсить глобальный рейтинг top.mail по ключевым словам, в той же самой вкладке в KeyCollector.
На этом бесплатный сбор ключевых слов у конкурентов закончен. Теперь его надо очистить и оставить только нужное.
В итоге получаем готовый список ключевых слов конкурентов, которыми можем дополнить наше ядро.
Как составить семантическое ядро
Схема простая: нужно определить маркеры и расширить их.
Маркерные запросы обычно являются ВЧ фразами, характеризующими раздел или подраздел каталога на сайте. Часто это заголовок H1 страницы. Собрать маркеры проще и эффективнее всего у конкурентов из ТОП-10. Проанализировав их СЯ и структуру, вы получите основу, которую затем сможете расширить и улучшить.
Для раздела «Пылесосы» маркерами будут:
- Роботы-пылесосы;
- Моющие пылесосы;
- Вертикальные пылесосы.
Далее к маркерам нужно добавить синонимы и альтернативные названия услуг и товаров.
Пример:
- двигатель – мотор;
- ГРМ – газораспределительный механизм.
Собранный список маркеров еще не семантическое ядро. Его нужно расширить с помощью облака запросов – менее частотных и более понятных фраз. Как правило, они состоят из маркера и пары уточняющих слов. Их сбор можно автоматизировать.
Плюсы и минусы анализа семантического ядра конкурентов с помощью специальных сервисов
Многие программы, определяющие ключевые слова на сторонних сайтах, работают по следующему принципу:
- Составляется перечень самых частых поисковых запросов.
- Отбирается 1−10 страниц выдачи для каждого из них.
- Сбор выдачи ключей повторяют с установленной периодичностью: неделя, месяц или год.
Подобный подход имеет свои минусы. Так, программы:
- выдают только видимую часть поисковых запросов на сайтах компаний-конкурентов;
- сохраняют у себя своего рода «шаблон» выдачи, сформированный при сборе ключей;
- способны определять видимость лишь тех поисковых запросов, которые есть в их базах;
- показывают только известные им ключи.
Кроме того:
- чтобы получить достоверные данные о ключах на сайте компании-конкурента, надо знать, когда собираются поисковые запросы (анализируется видимость);
- не все запросы отражаются в поисковой выдаче, и потому программе они не видны. Это может происходить по разным причинам: страницы сайта еще не проиндексированы, поисковая система не ранжирует их из-за длительной загрузки, содержания вирусов и т. д.;
- сведений о том, какие ключевые запросы включены в базу сервиса, используемого для сбора поисковой выдачи, как правило, нет.
То есть программа составляет не достоверное семантическое ядро, положенное в основу сайта, а только его малую видимую часть.

Основываясь на вышеизложенном, можно сказать следующее:
- Семантика конкурирующего сайта, сформированная при помощи специализированных программ, не дает полной актуальной картины.
- Чем более обширна база ключевых слов в программе, тем медленнее обрабатывается выдача и тем менее актуальна семантика. Пока программа формирует поисковую выдачу по началу базы, сведения по концу баз теряют актуальность.
- Программы не разглашают сведения о том, актуальны ли их базы и когда было последнее обновление. Поэтому вам не может быть известно, насколько ключи с конкурирующего сайта, отобранные программой, отражают его реальную семантику.
Но существенным плюсом такого подхода можно назвать получение доступа к большому количеству ключей конкурентов, многие из которых вы можете применять, чтобы расширять семантическое ядро своего сайта. Помимо этого, проверка семантики конкурирующего ресурса позволяет дополнить семантику вашей веб-площадки или проанализировать маркетинговую политику компаний-соперников.
Для чего нужно семантическое ядро
Думаю, разглагольствовать на тему для чего нужно семантическое ядро и стоит ли вообще заниматься его сбором, не нужно. Исходя из содержания статьи, можно понять, что семантическое ядро – ключ к продвижению сайта и его юзабилити с точки зрения не только скрытой семантики SEO и поисковых роботов, но и пользователей, которые будут этот сайт посещать и становиться потенциальными клиентами.
Как мы уже говорили, главное в продвижении – заявки и продажи с сайта. Продвинуть в топ мало, нужно знать, по каким именно ключевым запросам это нужно делать. Поэтому, сбор семантики для сайта происходит, исходя из частотности.

Даже в настройке рекламы, хоть контекстной, хоть в РСЯ, специалист должен знать интересы пользователя, и какие запросы его чаще всего интересуют. Многие опытные SMM-специалисты, таргетологи, как и часто называют, очень плотно работают с семантикой.
Автоматический сбор семантического ядра онлайн
А теперь поговорим о самых востребованных сервисах по сбору семантического ядра.
Wordstat
Эту программу можно считать первоисточником, поскольку другие инструменты так или иначе взаимодействуют с данными поисковой системы. В первую очередь выберите несколько запросов, максимально точно отражающих суть вашего бизнеса. Допустим, вы продаете цифровые фотоаппараты. Представьте, что лично ищете любой аналогичный магазин в Интернете. В качестве примера приведем запрос «купить фотоаппарат».
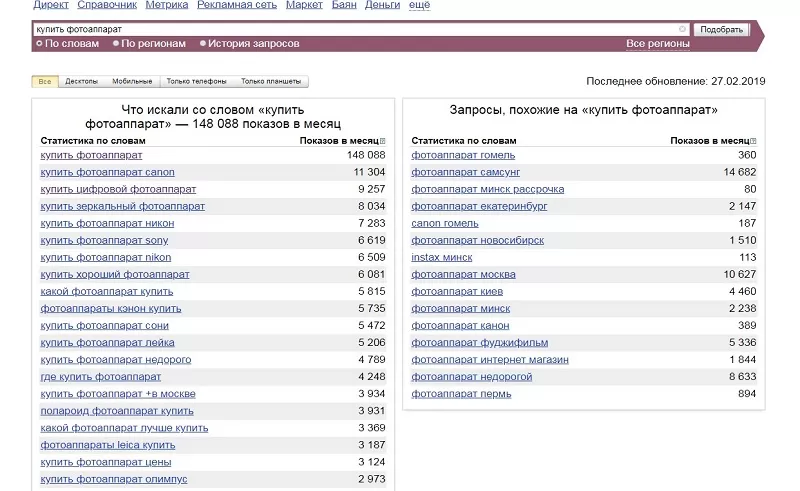
Слева в колонке – фразы, которые аудитория искала вместе с фразой «купить фотоаппарат». Не забывайте, что из перечня полученных фраз надо отсеять все лишние запросы. Вы ведь не продаете фотоаппараты на Avito?
Если вы не уверены, к какой категории относится запрос (коммерческий он или нет), просто впишите его в строку поиска и проанализируйте результаты выдачи. Если в ней больше блогов и журналов, то запрос, по всей вероятности, информационный. Например, в ключи может попасть фраза «какой фотоаппарат купить в 2019 году».
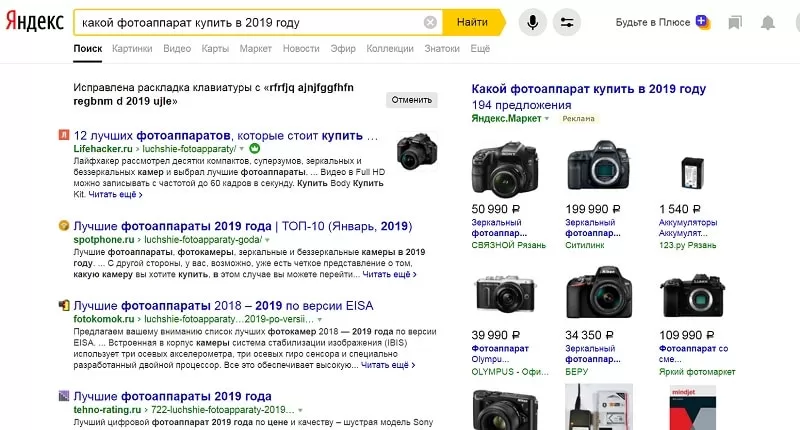
По запросу «какой цифровой фотоаппарат купить в 2019 году» поисковая система выдает только инфосайты.
Давайте подробнее поговорим о Wordstat как о программе для сбора семантического ядра. В колонке справа указаны фразы, схожие с начальным запросом. Но лишнего здесь, конечно, больше. Ваша задача – пользоваться только теми фразами, которые реально отражают специфику бизнеса, и, безусловно, исключать инфозапросы типа «качественный фотоаппарат». Правой колонкой можете пользоваться, чтобы искать синонимы. К примеру, мало кто может с первого раза правильно написать название японской марки fujifilm. Встречаются запросы «фиджифильм», «фудзифилм» и т. п. Все эти вариации также нужно включить в состав семантического ядра.
Анализируя запросы, вы обязательно увидите, что пользователи ищут фототехнику по ряду определенных критериев:
- стоимость (купить недорого);
- марка (купить фотоаппарат самсунг, кэнон, сони);
- модель (купить фотоаппарат canon powershot);
- характеристики (купить цифровой фотоаппарат, купить зеркальный фотоаппарат);
- регион (купить фотоаппарат в казани, купить фотоаппарат в краснодаре).
Эти данные позволяют вам сформировать так называемые маски запросов, в частности:
- фотоаппарат + действие (купить, заказать, с доставкой по РФ);
- фотоаппарат + стоимость (недорого, дешево, по акции, до 10 тыс., до 50 тыс.);
- фотоаппарат + марка;
- фотоаппарат + марка + модель;
- фотоаппарат + характеристика (64 гб, с nfc, 12 дюймов, с двумя симками);
- фотоаппарат + еще какой-то запрос (легкий, в качестве подарка).
Определив маски запросов, вы:
- Грамотно распределите посадочные страницы на сайте по категориям и характеристикам товаров.
- Разработаете страницы под популярные поисковые запросы (например, недорогой фотоаппарат).
- Растиражируете выбранные маски запросов на все остальные группы товаров.
- Сделаете шаблон для сбора семантического ядра.
На этой ступени мы не советуем сильно акцентировать внимание на частотности запроса. В список можете включать любые непустые фразы (с частотой от 1), связанные с вашим бизнес-проектом
При помощи каких фраз вы продвигаете и рекламируете свой товар, дело второе. На данном этапе главная задача – сбор полноценного семантического ядра.
RushAnalytics
Программа Rush Analytics помогает сделать сбор запросов из левой колонки Wordstat более автоматизированным с последующей загрузкой данных в таблицу Excel.
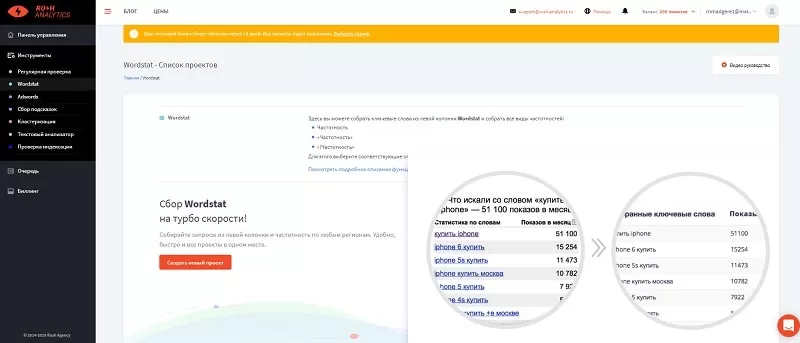
В нашем примере нужно лишь запустить сбор ключей по запросам «фотоаппарат». Но есть одна важная деталь. Wordstat по умолчанию отдает всего 41 страницу с результатами. Как вы понимаете, все запросы по такой схеме получить не удастся. Для обхода ограничения необходимо воспользоваться методом сбора частотности для запросов заданной длины (до 7 слов).
Для этого следует добавить запросы в Wordstat таким образом (обязательно нужны кавычки):
- «фотоаппарат фотоаппарат»;
- «фотоаппарат фотоаппарат фотоаппарат»;
- «фотоаппарат фотоаппарат фотоаппарат, фотоаппарат»;
- и так далее – до 7 слов.
Этот метод поможет в сборе максимального количества запросов по вашей теме.
Spywords.ru
Программа spywords.ru дает возможность несколько облегчить себе задачу и собрать семантическое ядро не с нуля, а с помощью сайтов-конкурентов.

Принцип работы предельно прост: нужно выбрать 3–4 лидера в вашей отрасли и собрать все фразы, по которым их ранжируют поисковики в пределах Топ-100.
Конечно, так вы, скорее всего, не соберете полноценную семантику. Но с большой долей вероятности охватите процентов 60, и для начала этого достаточно.
Что такое семантическое ядро простыми словами
Как это ни странно, но семантическое ядро – это обычный excel файл, в котором списком представлены ключевые запросы, по которым вы (или ваш копирайтер) будете писать статьи для сайта.
Вот как, например, выглядит мое семантическое ядро:

Зеленым цветом у меня помечены те ключевые запросы, по которым я уже написал статьи. Желтым – те, которым статьи собираюсь написать в ближайшее время. А бесцветные ячейки – это значит, что до этих запросов дело дойдет немного позже.
Для каждого ключевого запроса у меня определена частотность, конкурентность, и придуман “цепляющий” заголовок. Вот примерно такой же файл должен получиться и у вас. Сейчас у меня СЯ состоит из 150 ключевиков. Это значит, что я обеспечен “материалом” минимум на 5 месяцев вперед (если даже буду писать по одной статье в день).
Чуть ниже мы поговорим о том, к чему вам готовиться, если вы вдруг решите заказать сбор семантического ядра у специалистов. Здесь скажу кратко – вам дадут такой же список, но только на тысячи “ключей”
Однако, в СЯ важно не количество, а качество. И мы с вами будем ориентироваться именно на это
Зачем вообще нужно семантическое ядро?
А в самом деле, зачем нам эти мучения? Можно же, в конце концов, просто так писать качественные статьи, и привлекать этим аудиторию, правильно? Да, писать можно, а вот привлекать не получится.
Главная ошибка 90% блогеров – это как раз написание просто качественных статей. Я не шучу, у них реально интересные и полезные материалы. Вот только поисковые системы об этом не знают. Они же не экстрасенсы, а всего лишь роботы. Соответственно они и не ставят вашу статью в ТОП.
Здесь есть еще один тонкий момент с заголовком. Например, у вас есть очень качественная статья на тему “Как правильно вести бизнес в “мордокниге”. Там вы очень подробно и профессионально расписываете все про фейсбук. В том числе и то, как там продвигать сообщества. Ваша статья – самая качественная, полезная и интересная в интернете на эту тему. Никто и рядом с вами не валялся. Но вам это все равно не поможет.
Почему качественные статьи вылетают из ТОПа
Представьте, что на ваш сайт зашел не робот, а живой проверяльщик (асессор) с Яндекса. Он понял, что у вас самая классная статья. И рукам поставил вас на первое место в выдаче по запросу “Продвижение сообщества в фейсбук”.
Знаете, что произойдет дальше? Вы оттуда все равно очень скоро вылетите. Потому что по вашей статье, даже на первом месте, никто не будет кликать. Люди вводят запрос “Продвижение сообщества в фейсбук”, а у вас заголовок – “Как правильно вести бизнес в “мордокниге”. Оригинально, свежо, забавно, но… не под запрос. Люди хотят видеть именно то, что они искали, а не ваш креатив.
Соответственно, ваша статья будет вхолостую занимать место в ТОП выдачи. И живой асессор, горячий поклонник вашего творчества, может сколько угодно умолять начальство оставить вас хотя бы в ТОП-10. Но не поможет. Все первые места займут пустые, как шелуха от семечек, статейки, которые друг у друга переписали вчерашние школьники.
Зато у этих статей будет правильный “релевантный” заголовок – “Продвижение сообщества в фейсбук с нуля” (по шагам, за 5 шагов, от А до Я, бесплатно и пр.) Обидно? Еще бы. Ну так боритесь против несправедливости. Давайте составим грамотное семантическое ядро, чтобы ваши статьи занимали заслуженные первые места.
Еще одна причина начать составлять СЯ прямо сейчас
Есть еще одна вещь, о которой почему-то люди мало задумываются. Вам надо писать статьи часто – как минимум каждую неделю, а лучше 2-3 раза в неделю, чтобы набрать побольше трафика и побыстрее.
Все это знают, но почти никто этого не делает. А все потому, что у них “творческий застой”, “никак не могут себя заставить”, “просто лень”. А на самом деле вся проблема именно в отсутствие конкретного семантического ядра.
Наше СЯ – это как контент-план для социальных сетей. То есть там написано конкретно, что мы будем делать в ближайшие 2-3 месяца. Нам не надо будет садиться с утра и начать выдумывать тему для нового поста. У нас все придумано, продумано и прочитано.
Именно это и спасет вас от так называемого “творческого кризиса”. Когда вы точно знаете, что вам делать – становится гораздо легче. Поэтому ни в коем случае не пропускайте этап создания семантического ядра (каким бы муторным вам это дело не показалось). Потом вам все равно придется подбирать темы и запросы, но только потратите вы на это в десять раз больше времени и сил.
А теперь. собственно, давайте разберем, как правильно составить семантическое ядро с нуля.
Wordstat Яндекса и расширения для браузера
Wordstat — это бесплатный сервис поисковой статистики и подбора слов от Яндекса. Именно здесь можно посмотреть статистику запросов по любой поисковой фразе в зависимости от региона поиска.
Чтобы собрать семантическое ядро, используя исключительно Wordstat Яндекса, нужно копировать каждую страницу с результатами, переносить ее в Excel, а затем отсеивать нерелевантные запросы и только после этого добавлять в рекламные кампании.
Сократить процесс в несколько раз поможет расширение для браузера WordStater. После его установки Wordstat выглядит так:

Расширение позволяет одновременно собирать поисковые фразы, их частотность и минус-слова. При добавлении они будут подсвечены красным на всех страницах.

Далеко не всегда суть поискового запроса можно понять сразу же, иногда приходится копировать и искать его в новой вкладке. Разработчики расширения продумали этот момент — создали переход по нужному ключевому слову прямо из интерфейса при помощи одного клика. Это удобно и значительно экономит время.
Другие расширения с подобными возможностями:
- Yandex Wordstat Helper
- Yandex Wordstat Assistant
- Yandex Wordstat Keywords Add
Этапы работы с семантическим ядром
Теперь когда мы знаем, что такое семядро и для чего оно нужно, а также знакомы с основными классификациями запросов, давайте вкратце разберём основные этапы работы с ядром.
Сбор семантики
Подробные способы сбора семантики будут даны в части «», здесь же мы остановимся на основных моментах.
На этом этапе вы должны найти и выписать общие запросы (их ещё называют маркерными), которые характеризуют деятельность вашего бизнеса: как общие направления, так и отдельные услуги и товары.
Например, вы продаёте мотоциклы определённой компании. Вашими маркерными запросами могут являться «мотоциклы», «мотоциклы + бренд» , «как выбрать мотоцикл», «запчасти для мотоцикла + бренд», «как ухаживать за мотоциклом», «классические/спортивные/круизёры и другие типы мотоциклов», «ремонт мотоциклов + бренд» и т.д. То есть в зависимости от оказываемых услуг или имеющихся товаров выбираются соответствующие маркеры.
После определения маркерных запросов проверяйте собранные ключевые слова в основных сервисах статистики запросов: Яндекс.Вордстат или Google Ads Планировщик ключевых слов. В них вы найдёте как частотность запросов, так и варианты других ключевых слов по вашей тематике. Собирайте всё, что как-то связано с вашим бизнесом.
Принципиальная разница между обозначенными сервисами заключается в следующем:
- Статистика в каждом актуальна только для родной поисковой системы. То есть если запрос «юридические услуги» смотреть в Вордстате, то показов будет более 100 000 именно в Яндекс. В Планировщике ключевых слов значения соответственно будут отличаться в Google.
- Плюс Вордстата в том, что он показывает точное значение показов запроса. Если у вас новый аккаунт в Google Ads, вместо точных значений запроса вы получите диапазоны типа 10–100, 100–1000 и т.д.
- Плюс Планировщика ключевых слов в том, что он даёт множество вариантов ключей сразу, чтобы учесть все варианты запросов для вашего сайта в продвижении и рекламе.
Если денег на платные инструменты нет, советуем использовать сразу 2 сервиса при сборе семантики. Но всё же рекомендуем купить Key Collector. Его основная задача — это автоматический сбор (парсинг) ключевых слов не только с Вордстата и Планировщика, но и с других сервисов и баз. Это не реклама данного инструмента, но уточним, что, кроме парсинга, сервис удобен для чистки и кластеризации ядра. Для многих SEO-специалистов Key Collector как швейцарский нож.
 Интерфейс KeyCollector
Интерфейс KeyCollector
Очистка
Когда все варианты запросов пользователей собраны в одной таблице, наступает время чистки от лишнего.
Лишними являются запросы, которые:
- слишком общие,
- не относятся к деятельности вашего сайта,
- не подходят по географии,
- включают в себя неактуальные цифры и даты,
- имеют брендовые составляющие конкурентов,
- состоят из 8 слов и более,
- затруднительно использовать на одной странице.
В качестве примера приведём подобранные ключи для одной из компаний, которая занимается продажей электрических каминов в Санкт-Петербурге:
Кластеризация и выбор страниц
Кластеризация — это группировка запросов по общности их смысловых значений в иерархическом порядке. То есть в одном кластере, или группе, должны быть запросы, описывающие одну сущность в глазах пользователя и поисковой системы. Делается это либо вручную, либо с помощью специальных сервисов.
Вернёмся к нашим каминам и возьмём следующие запросы:
- камин электрический с эффектом пламени;
- камины электрические с эффектом живого пламени;
- камины электрические фото;
- купить камин электрический;
- камин электрический купить в спб;
- угловой камин электрический;
- угловые камины электрические купить.
Первые два запроса можно объединить в один кластер и продвигать на одной странице. 3-й предполагает галерею или каталог, 4 и 5-й маркерные и достаточно общие, поэтому для них подойдёт главная страница или каталог. 6 и 7-й описывают категорию электрокаминов и под них стоит создать отдельную страницу на сайте.
Это пример ручной кластеризации, но мы указали, что запросы должны описывать одну сущность и в глазах пользователя, и поисковика. И вот тут начинаются проблемы, потому что часто можно столкнуться с тем, что схожие на первый взгляд запросы формируют разную поисковую выдачу. Чтобы избежать таких ошибок, используются специальные сервисы кластеризации, которые сравнивают выдачу и группируют кластеры.
Мониторинг
Важно не просто собрать ключевые слова и использовать их в создании контента для сайта, но и отслеживать рост позиций и трафика по этим запросам. О том, как это делать и какие сервисы можно использовать, читайте в нашей статье про проверку позиций

Оценка стоимости продвижения запроса
После того, как Вы откорректировали список, убрав слова с малой частотой, необходимо проверить, какие ресурсы (в основном денежные) необходимо затратить, чтобы продвинуть целевые страницы в поисковых системах. Оценить стоимость продвижения можно исходя из ссылочной стоимости каждого ключевого слова по seo-агрегаторам (например, Rookee, SeoPult). Воспользуемся инструментами сервис SeoPult и посмотрим, какие ключевые слова следует исключить в связи с большими затратами на продвижение.
Работать в этом seo-агрегаторе можно только зарегистрированным пользователям. Поэтому проходим регистрацию и добавляем новый проект (рисунок 12).
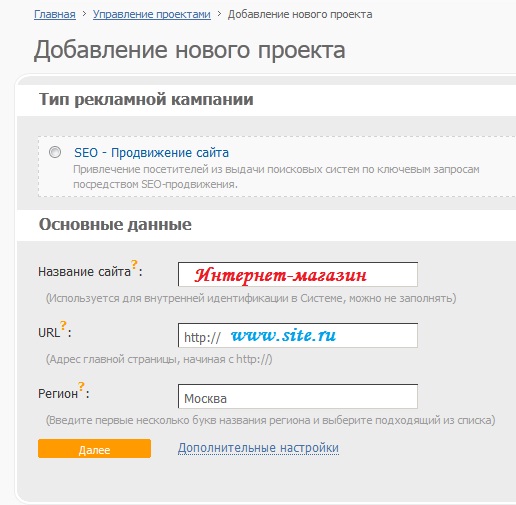
Рисунок 12. Начинаем новый проект в сервисе SeoPult
Если Вы работаете над созданием семантического ядра веб-ресурса, которого еще нет в индексе поисковых систем, в поле url сайта введите адрес любого проиндексированного сайта. Главное в таком случае, чтобы выбранный вами сайт относился к тому же региону, для которого мы проверяли частотность ключевых слов.
На следующей странице нашего проекта необходимо правильно добавить ключи, выбрать количество позиций в топе и нажать кнопку для подсчета прогнозируемой стоимости одного перехода с поисковых систем (рисунок 13).
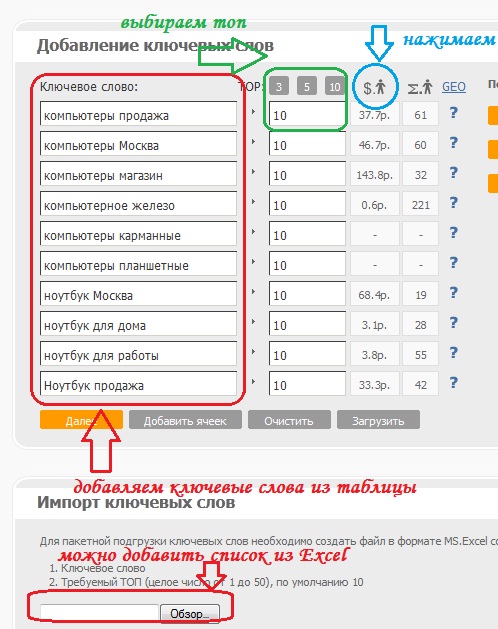
Рисунок 13. Действия для подсчета бюджета по ключевым словам ядра
На рисунке видно, что ряд ключевых запросов имеют большую стоимость перехода, по сравнению с другими словами. Это говорит о том, что эти запросы являются высококонкурентными в своей тематике. Поэтому и требуют таких вложений для успешного продвижения внешними ссылками. Для целевых страниц с низкочастотными ключевиками подойдут слова со стоимостью не больше 5-10 рублей за клик. Обычно хватает грамотной внутренней перелинковки и пару внешних ссылок, чтобы эти страницы попали в топ-10.
Просмотрев таким образов все ключевые слова из списка масок, следует сгруппировать высоко- средне- и низкоконкурентные запросы исходя из цифр ссылочной стоимости фразы. Теперь у Вас есть готовое семантическое ядро сайта. Осталось выбрать целевые страницы для продвижения, наполнить страницы уникальным контентом, провести их оптимизацию и проиндексировать в поисковых системах.
Выводы
Давайте подытожим вышесказанное — у нас получится краткий мануал по составлению семантического ядра:
- Анализируем тематику сайта. Такой анализ позволяет создать первоначальный список слов, которые описывают тематику и направление деятельности Вашего сайта.
- Дополняем первоначальный список различными дополнительными словами (синонимы, термины, морфологические изменения слов и т.д.)
- Составляем правильный список запросов.
- Производим зачистку семантического ядра, исключая слова-пустышки и ключевые слова, у которых число показов в месяц меньше заданной величины.
- Оцениваем стоимость продвижения каждого ключевого слова, формируя списки ключей с разной конурентностью.
На этом наша небольшая практика в подборе ключевых слов для ядра завершена. Как видите, составление семантического ядра является хоть и трудоемким, но не сложным делом. Главное — это выработать свой четкий план, сделать свой мануал и придерживаться его.
Где можно заказать отличное семантическое ядро?
Если же у Вас нет времени на сбор полноценного ядра, я с удовольствием помогу это сделать.
Что такое кластеризация семантического ядра
Кластеризацией семантического ядра называется распределение общего числа запросов на группы в соответствии с определёнными принципами. Представьте огромный склад с бытовой химией, где находится абсолютно всё: средства для ухода за телом, принадлежности для уборки, стирки, так же химические средства по борьбе с различными насекомыми.
Чтобы ориентироваться во всём этом и оперативно находится нужный товар, необходимо их рассортировать по назначению, ценовой категории, объёму, качеству и т.д. Так же и семантикой. Когда происходит сбор ключевых запросов, туда входит всё: коммерческие, информационные запросы, так же фразы, отдельные слова, и даже запросы с ошибками, в общем всё, чем когда-либо интересовался пользователь.

Человеческий мозг постоянно генерирует всё новые и новые запросы и фразы и в связи с этим семантическое ядро постоянно пополняется новыми «ключами» и сортируется в соответствии со спецификой. Пользователь, сам того не подозревая, когда ищет в интернете запрос информационного характера, может стать потенциальным клиентом, если правильно выстроить структуру запроса и сделать посадочные страницы, так же интересный сайт.