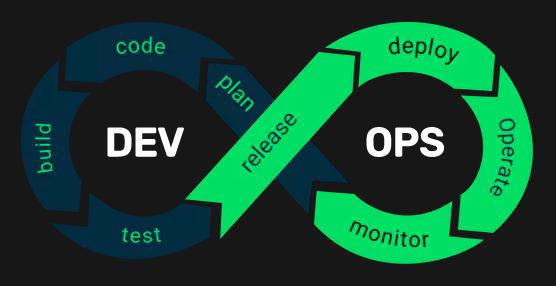
Devops
Содержание:
- Сколько вешать в граммах
- Skillfactory
- Решение проблемы идентичности сред в DevOps методологии
- ЧОУ ДПО ИПАП
- Эволюция процесса деплоя в проекте
- Денис Яковлев (2ГИС)
- С низов ИТ до DevOps-инженера
- DevOps and site reliability engineering (SRE)
- Otus
- iTerm || Terminal || Console
- Каким должен быть DevOps-специалист
- Утилиты для обработки JSON
- Swarming на практике: пример структуры для DevOps
- Docker в работе. Взгляд на его использование в Badoo (год спустя)
- Антон Турецкий (Badoo)
- Самые распространенные возражения
- Заключение
Сколько вешать в граммах
Разброс предлагаемых зарплат для указанных вакансий — 90к-200к
Теперь хотелось бы провести параллель между денежными вознаграждениями Системных Администраторов и DevOps Engineers.
В принципе, для упрощения можно грейды по опыту работы раскидать, хоть это и не будет точным, для целей статьи хватит.
Опыт:
- до 3-х лет — Junior
- до 6-ти лет — Middle
- более 6-ти — Senior
Сайт поиска сотрудников предлагает:
System Adminsitrators:
- Junior — 2 года — 50к руб.
- Middle — 5 лет — 70к руб.
- Senior — 11 лет — 100к руб.
DevOps Engineers:
- Junior — 2 года — 100к руб.
- Middle — 3 года — 160к руб.
- Senior — 6 лет — 220к руб.
По стажу «DevOps»’ов использовался стаж, хоть как то затрагивающий SDLC.
Из вышеозначенного следует, что на самом деле компаниям не нужны DevOps’ы, а также что они могли сэкономить не менее 50 процентов от изначально запланированных затрат, наняв именно Администратора, более того, они могли бы четче определить обязанности искомого человека и быстрее закрыть потребность. Не стоит также забывать, что четкое разделение ответственности позволяет снизить требования к персоналу, а также создать более благоприятную атмосферу в коллективе, ввиду отсутствия пересечений. В подавляющем большинстве вакансии пестрят утилитами и DevOps лейблами, однако не имеющие в основе действительно требования к DevOps Engineer, лишь запросы на тулзового администратора.
Процесс обучения DevOps инженеров также ограничен лишь набором специфичных работ, утилит, не дает общего понимания процессов и их зависимостей. Это конечно хорошо, когда человек может используя Terraform задеплоить AWS EKS, в связке с Fluentd сайд-каром в этом кластере и AWS ELK стеком для системы логирования за 10 минут, используя лишь одну команду в консоли, но если он не будет понимать сам принцип обработки логов и для чего они нужны, не знать как собирать метрики по ним и отслеживать деградацию сервиса, то это будет все тот же эникей, умеющий использовать некоторые утилиты.
Спрос, однако, порождает предложение, и мы видим крайне перегретый рынок позиции DevOps, где требования не соответствуют реальной роли, а лишь позволяют системным администраторам зарабатывать больше.
Так кто же они? DevOps’ы или жадные системные администраторы? =)
Skillfactory
Профессия DevOps-инженер
Освойте перспективную IT-профессию на стыке разработки, системного администрирования и бизнеса
За 6 месяцев обучения 6вы освоите ключевые инструменты и самые востребованные рынком технологии:
- Модули с необходимой теорией и интерактивные вебинары, где вы будете разбирать тонкости использования технологий Jenkins, Docker, Kubernetes, Ansible, Terraform. Вся теория и практика приближены к реальному продакшну.
- Программа насыщена практикой, чтобы освоить и отточить каждую из задач: от поднятия веб-сервера до балансировки нагрузок на highload-системы. Для тех, кто захочет углубиться в отдельные технологии, готовы списки полезных материалов.
- Вы создадите портфолио архитектурных решений и подходов и сможете уверенно рассказывать о них на собеседовании или осознанно внедрять у себя в проекте.
- Вы разберётесь в построении эффективного CI/CD-пайплайна, который сам собирает проект, вовремя оповещает участников разработки об изменениях или проблемах, отвечает на вопросы менеджмента «сколько», «когда» и «почему».
Преимущества:
- Персонального тьютора, который следит за вашим прогрессом и остается с вами на связи весь курс
- Личные консультации с менторами и постоянная обратная связь по проделанной работе
- Дружное сообщество, которое общается 24/7 в Slack и на вебинарах
- Поддержку по всем учебным вопросам в течение 1 часа в рабочее время
- Групповые проекты и работа в командах
Решение проблемы идентичности сред в DevOps методологии
Сегодня многие говорят о DevOps как о методологии, которая помогает разрушить «железный занавес» между IT отделом, QA и программистами и создать некий общий механизм, помогающий делать продукты быстрее и качественнее. Основная задача, которая встает перед DevOps разработчиком — это добиться максимальной автоматизации развертывания development. testing, production сред и переходов между ними. Соответственно одна из основных проблем в данном случае — это соблюсти полную идентичность сред разработки, тестирования и эксплуатации. Под катом приведу пример практического решения данной задачи, которое я использовал в нескольких компаниях в ходе интеграции DevOps методологии.
ЧОУ ДПО ИПАП
DevOps связывает этапы работы над IT-продуктом: разработка, тестирование, администрирование и новая разработка. Должность «девопса» в IT-компании спасает от авралов, глобальных поломок и помогает развивать продукт эволюционно.
Новое время диктует новые подходы к разработке внедрению и интеграции программного обеспечения. В связи с этим на рынке требуются специалисты нового формата. В новом курсе от ИПАП за основу берется базовый курс по LINUX, на основе полученных знаний начиная с 4 модуля разбираются непосредственно DevOPS подходы и методологии.
Пройдя курс, слушатель получает хорошие знания по OS Linux, а так же знания, соответствующие современным требованиям к DevOPS специалисту.
Методика DevOps актуальна для всех проектов, связанных с программным обеспечением, вне зависимости от архитектуры, платформы и поставленной цели. Типичные варианты применения: облачные и мобильные приложения, интеграция приложений, модернизация и управление мультиоблаком.
По окончании курса вы освоите новую востребованную на IT-рынке профессию — сможете решать инфраструктурные задачи, находить новые инструменты и подходы для наиболее быстрой доставки продукта до пользователей.
Эволюция процесса деплоя в проекте
Денис Яковлев (2ГИС)
Меня зовут Денис, я работаю в компании 2ГИС, около полутора лет занимаюсь вопросами continuous delivery для проектов веб-отдела. До этого работал в компании Parallels и там прошел путь от QA инженера до team lead’а.
Про deploy. Если мы с вами выпускаем не коробочный продукт, а пишем какой-нибудь сервис, который работает где-то, как многие называют, в дикой природе, на серверах, куда заходят пользователи, то нам недостаточно просто разработать этот сервис и протестировать, нам нужно еще его в эту дикую природу как-то задеплоить, т.е. доставить туда код вместе со всем необходимым для его работы.
Из чего это состоит? Нам нужно доставить, прежде всего, код — то, над чем мы работали большое количество времени, тестировали и прочее.
С низов ИТ до DevOps-инженера
Вадим Князев, DevOps-инженер «Нетологии-групп»:
| Недавно я заполнял заявку на кредит и в графе «ваша должность» не было DevOps-инженера. Это я к тому, что такая профессия до сих пор не оформлена официально: есть системный инженер, кем я и являюсь. Если системный инженер участвует в проекте, где разработку ведут по методологии DevOps, то его автоматически называют DevOps-инженером. |
Вадим Князев говорит, что он начинал с самых низов ИТ-фирмы: сначала был оператором call-центра и помогал перезагружать роутеры. Образование у него непрофильное (инженер-физик), поэтому знаний в ИТ практически не было.
| Но я смотрел на коллег-разработчиков и системных инженеров и очень хотел разобраться, как все устроено. В перерыве между перезагрузками роутеров что-то читал, приставал с вопросами к коллегам, пытался делать сам — покупал старые компьютеры, объединял их в сеть, пробовал поднимать разные приложения, сначала все руками, потом показали, что есть менеджеры конфигураций, тогда первый раз попробовал Puppet. В итоге перешел с первого уровня поддержки на второй. Там уже приходилось решать более сложные технические вопросы. Затем меня повысили до системного администратора, и я стал поддерживать инфраструктуру, — рассказывает Князев. |
Работа разработчиком ему казалось скучной: «у тебя пара строчек кода, за которые ты отвечаешь, и все». А у системного инженера во власти целая интересная инфраструктура со своими особенностями, а также куча серверов, которые взаимодействуют друг с другом.
 Работа разработчиком Владимиру Князеву казалась скучной
Работа разработчиком Владимиру Князеву казалась скучной
На первом месте работы Вадим Князев долго продвигал идею, что сборкой, тестированием и деплоем должны заниматься отдельные люди, а разработчики должны только писать код. Он предлагал пайплайны сборок, системы для автоматизации тестирования, мониторинга, сбора логов, но команда к этому не была готова, не шла на контакт.
| Поэтому я перешел в другую компанию, в которой влился в команду инженеров с DevOps-уклоном. Путь от оператора call-центра до команды с DevOps занял у меня 2 года. Потом меня позвали в стартап, в котором как раз пришлось все поднимать с нуля. Все получилось, работает и развивается до сих пор, — говорит Вадим Князев. |
В «Нетологию-групп» он пришел уже на работающую инфраструктуру, нужно было только все поддерживать и развивать. Князев считает, что делать все с нуля гораздо проще, чем принимать то, что уже работает. Зачастую приходится изучать новые инструменты и подходы, которые были внедрены до тебя. Самой большой трудностью для него стал Kubernetes: «я много читал о нем, всегда хотел попробовать, но предыдущие проекты не позволяли его использовать. У меня был страх, что я не разберусь, но когда на собеседовании меня спросили «А не боишься, что не разберешься?», я ответил, что не боюсь. Пришлось разобраться».
С момента прихода Вадима в команду «Нетологии-групп» прошло два года. И сейчас в компании понимают, что ему — единственному человеку на DevOps для всей компании — постепенно будет еще тяжелее: количество проектов растет, инфраструктура усложняется, а за последние пару лет внутри «Нетологии-групп» появились еще две компании с разными задачами, рассказывает Дмитрий Меремьянин. Поэтому компания начала искать ему человека в помощь. Искали долго, около полугода. Опять же из-за специфики рынка — хороших специалистов, которые подходили бы, не так много.
| Но как я и говорил выше, главное, что я хочу пожелать компаниям, которые начинают развивать DevOps-культуру, — это терпение. Хорошего специалиста найти можно, но это занимает время. С другой стороны, процесс изучения навыков и компетенций соискателей приносит пользу, вы можете оценить свои требования к инженерам, соотнести их с требованиями рынка и, возможно, перенять для себя какие-то новые инструменты, — отмечает Дмитрий Меремьянин. |
Источник фото — «Нетология-групп»
DevOps and site reliability engineering (SRE)
Site reliability engineering (SRE) uses software engineering techniques to automate IT operations tasks — e.g. production system management, change management, incident response, even emergency response — that might otherwise be performed manually by systems administrators. SRE seeks to transform the classical system administrator into an engineer.
The ultimate goal of SRE is similar to the goal of DevOps, but more specific: SRE aims to balance an organization’s desire for rapid application development with its need to meet performance and availability levels specified in service level agreements (SLAs) with customers and end-users.
Site reliability engineers achieve this balance by determining an acceptable level of operational risk caused by applications — called an ‘error budget’ — and by automating operations to meet that level.
On a cross-functional DevOps team, SRE can serve as a bridge between development and operations, providing the metrics and automation the team needs to push code changes and new features through the DevOps pipeline as quickly as possible, without ‘breaking’ the terms of the organizations SLAs.
Otus
Если вы хотите развиваться в DevOps практиках, какие инструменты осваивать и как добиться быстрой обратной связи от вашего продукта и быстрого взаимодействия с клиентами — записывайтесь курс!
Программа создана специально для разработчиков, тестировщиков, системных администраторов и позволит на профессиональном уровне освоить инструменты и конкретные приёмы для реализации следующих практик:
- Infrastructure as Code(IaC),
- CI/CD,
- непрерывный сбор метрик (мониторинг и логирование).
- DevSecOps,
- SRE,
- проблема хранения «чувствительный данных»,
- инструментарий Loki, Vault, Vagrant, GCP components.
На курсе вы:
- детально разберете основные команды в Linux и научитесь работать в консоли
- познакомитесь с зомби, сиротами и демонами
- выясните, что такое ядро операционной системы и системные вызовы
- научитесь работать со стандартными потоками ввода/вывода
- разберете некоторые особенности файловой системы ext4
Программа курса составлена на основе опыта, накопленного компанией Экспресс 42, которая на протяжении уже более 5 лет помогает внедрять DevOps практики в крупных российских и зарубежных компаниях, готовит learned специалистов соответствующего профиля.
Практические задания будут выполняться с использованием Google Cloud Platform (GCP).
Для того, чтобы сделать использование ресурсов GCP бесплатным для участников курса, требуется наличие Google аккаунта, у которого не активирован бесплатный пробный период (free trial) в GCP. Free trial дает $300 на использование GCP в течение года. Для активации free trial необходима банковская карта для подтверждения личности.
Обучение проходит в формате онлайн-вебинаров. По всем практическим заданиям команда преподавателей дает развернутый фидбек.
Преподаватель — опытный engineer, который находится в едином коммуникационном пространстве с группой на протяжении всего курса, т. е. в процессе обучения слушатель может задавать уточняющие вопросы по материалам лекций и домашних заданий, взаимодействовать с преподавателями.
iTerm || Terminal || Console
Тут даже добавить нечего. Must have. Всегда и везде! Открытый терминал как старая привычка, где лучше написать пару команд, чем все делать в GUI интерфейсе. В жизни DevOps инженера всегда присутствует этот инструмент, невозможно обойтись без него. Проводя собеседования молодых системных инженеров сталкиваешься с тем, что они не так хорошо разбираются в консольных утилитах. Но DevOps — это не просто человек, который умеет настраивать Pipeline в CI/CD, но и тот, кто может провести дебаг в случае, если что-то не собирается или неправильно работает. Хорошие познания в Linux — очень важный скилл, который сильно помогает в ежедневной работе. В нашей компании у каждого DevOps-инженера не один год опыта системного администрирования.
Каким должен быть DevOps-специалист
Специалист, работающий с development and operations, в первую очередь должен не только знать инструменты, связанные с инфраструктурой, но и разбираться в системном администрировании. Если у специалиста этой базы нет, то появляется вопрос: как он смог вырасти до инженера по DevOps без понимания самого основного?
| По моему мнению, идеальный путь человека в DevOps — когда он сначала работает системным администратором и со временем сам понимает, какие «ручные» вещи можно автоматизировать. А после этого уже начинает пробовать и внедрять разные инструменты автоматизации в свои процессы. Так он развивает в себе эту культуру и вырастает в DevOps-инженера. Нельзя сказать, что такой путь априори правильный, но выглядит он сегодня логично, — считает Дмитрий Меремьянин. |
 По мнению Дмитрия Меремьянина, идеальный путь человека в DevOps начинается с работы системным администратором
По мнению Дмитрия Меремьянина, идеальный путь человека в DevOps начинается с работы системным администратором
Роман Гершкович, преподаватель «Нетологии», выделяет четыре качества, которые должны быть важны для руководителя при выборе специалиста:
1. Хорошая база и желание разбираться, как работают используемые компоненты.
| На мой взгляд, основная сложность состоит в том, чтобы найти людей с хорошей базой. Сейчас доступно множество готовых модулей, «строительных блоков» для любого инструмента управления конфигурациями, которые позволяют быстро получить сложную по устройству систему. Многие специалисты научились пользоваться подобными высокоуровневыми инструментами, но на этом остановились, не стали углубляться в принципы и результат их работы. А ведь это нужно для многих проектов: чтобы поддерживать и эффективно эксплуатировать сложную систему, минимизировать downtime, обязательно как минимум знать базовые вещи по Linux — какими ресурсами ОС управляет, как оценить их утилизацию, потребности приложений, наличие ошибок, и как их дебажить, — объясняет Роман Гершкович. |
2. Структурный подход к задачам.
Используя одни и те же инструменты, можно пойти по двум разным путям:
а) сделать удобную поддерживаемую структуру,
b) сделать бездумный copy-paste из мануала.
Оба этих способа приведут к работе системы в моменте. Однако, при внесении изменений в структуру, которая сделана по первому варианту, все будет быстро и просто, а со второй придется полдня просидеть, возможно все ломать и настраивать заново
Поэтому очень важно, чтобы специалист мыслил стратегически: мог определить, где он может скопировать элемент, а где такой шаг повлечет за собой негативные последствия в будущем, полагает Роман Гершкович
 Основная сложность состоит в том, чтобы найти людей с хорошей базой, считает Роман Гершкович
Основная сложность состоит в том, чтобы найти людей с хорошей базой, считает Роман Гершкович
3. Умение встроиться в действующую систему.
| У каждой команды и продукта своя история, экспертиза и use-кейсы. Поэтому практически по любому компоненту современных систем невозможно дать единственно верную оценку. В каждом конкретном случае иметь вес будут разные аспекты. Человек, которого вы нанимаете, должен это понимать. Даже если он суперпрофессионал в конкретной области с собственным мнением, он должен хотеть встроиться в команду с ее текущими правилами. Желание все действующее переделать, снести и построить заново только потому, что он лучше разбирается в Х, а не Y — губительно, — уверен Роман Гершкович. |
4. Желание человека постоянно развиваться
В команде хочется иметь людей, которые рассматривают работу не как место, где им нужно отсидеть 8 часов, а как увлечение, которым он горит. Инструменты постоянно меняются, их актуальность смещается, поэтому человек с интересом и желанием постоянно узнавать новое будет цениться в любой команде.
Настоящих специалистов, которые способны внедрять методологии DevOps в компанию, очень мало. Алексей Чувашов, CTO 65apps считает, что многие бывшие сисадмины просто учат новый и модный стек, но не пытаются понять процессы разработки и workflow задачи разработчиков. Еще меньше понимания у самих заказчиков или работодателей: зачем им нужен DevOps, какие задачи и потребности он должен закрывать.
При этом для DevOps-инженера очень важно, чтобы Dev-составляющая была на высоком уровне: должен быть опыт разработки, а также опыт работы в команде с разработчиками, понимание общих тенденций по выбранной специфике. На этапе общения с будущим работодателем лучше спросить, есть ли в их компании roadmap по развитию DevOps-направления.. Настоящих специалистов, которые способны внедрять методологии DevOps в компанию, очень мало, отмечает Алексей Чувашов
 Настоящих специалистов, которые способны внедрять методологии DevOps в компанию, очень мало, отмечает Алексей Чувашов
Настоящих специалистов, которые способны внедрять методологии DevOps в компанию, очень мало, отмечает Алексей Чувашов
Утилиты для обработки JSON
Перевод
Независимо от того, взаимодействуете ли вы с API или делаете запрос в базу данных, вы, вероятно, получите данные в формате JSON. Большинство популярных языков программирования имеют встроенные возможности для обработки и анализа JSON. Однако не всё так просто, если вы работаете с данными в Bash.
По умолчанию оболочки, такие как Bash, не имеют стандартного парсера JSON. Необходимо либо использовать интерпретатор языка программирования, либо установить соответствующую утилиту. Если вы хотите ограничиться возможностями командной строки, то установка утилиты, вероятно, будет самым простым вариантом. Вам не придется настраивать интерпретатор и устанавливать дополнительные зависимости.
Большинство специализированных утилит для работы с JSON также работают очень быстро, занимают мало места и не нуждаются в каких-либо дополнительных зависимостях.
В этой статье мы рассмотрим некоторые популярные утилиты, которые добавляют эту важную функцию в вашу оболочку командной строки. Это позволит вам обрабатывать данные JSON в скриптах.
Swarming на практике: пример структуры для DevOps
У Swarming нет единственной четко определенной структуры. Отчасти это объясняется новизной и, соответственно, малой распространенностью. Однако показанный ниже пример (основанный на swarming-методах поддержки пользователей, применяемых в BMC) является типичным. Он существенно улучшил работу службы поддержки (о чем было рассказано на UK’s Servicedesk and IT Support Show в 2015).
Swarming начинается при появлении проблемы, которую невозможно решить сразу в момент получения обращения от пользователя. Быстрая первичная сортировка задачи заканчивается ее отправкой в одну из двух групп (Swarms):
Первичная сортировка в структуре Swarm
Каждая группа (Swarm) — это небольшая команда, которая обрабатывает поступающие заявки в режиме, близком к реальному времени:
“Severity 1” Swarm (Группа по работе с инцидентами первой степени тяжести)
Три сотрудника, работающие в условиях запланированной еженедельной ротации.
Основное внимание: предоставить незамедлительный ответ, решить задачу как можно быстрее.
Эта группа нацелена на решение самых серьезных проблем. Ее участники координируют реакцию на сложные ситуации, подключают нужных людей, стараются организовать максимально быстрое решение критических проблем. Этот процесс не сильно отличается от процедуры реакции на серьезные происшествия (Major Incident), применяемой в традиционной многоуровневой модели. Однако параллельно развернута и другая группа, обрабатывающая гораздо большее количество обращений:
Dispatch Swarm (Группа диспетчеризации)
Проводит встречи каждые 60–90 минут.
Сфокусирована на регионах и продуктовых линейках.
Основное внимание: «схватить вишенку» (в первую очередь браться за то, что можно исправить очень быстро).
Вторичная задача: проверка обращений перед их отправкой командам поддержки продуктовых линеек.
Этот тип групп появился в качестве ответа на основную проблему многоуровневой поддержки: множество обращений, которые могли быть решены очень быстро при попадании к правильному специалисту, теряются в списках незавершенных задач. Таким образом, решение пятиминутного вопроса может растягиваться на дни.
Участников этой группы буквально подталкивают к тому, чтобы «хватать вишенки», не обращая внимания на проблемы, которые нельзя исправить мгновенно. Таким образом, время, затрачиваемое на решение значительного количества типов задач, может быть сильно сокращено.
Есть и дополнительная выгода. Включение в состав неопытных сотрудников приводит к тому, что они получают знания, доступ к которым в многоуровневой модели появился бы только при переводе в узкоспециализированную команду. В то же время высококвалифицированные специалисты третьего уровня поддержки оказываются ближе к клиенту.
Использование Dispatch Swarming приводит к быстрому решению значительного числа задач (в BMC их количество составляет примерно 30%), а оставшиеся обращения попадают в очереди более привычных команд поддержки, которые занимаются отдельными линейками продуктов. Здесь многие задачи будут знакомы и понятны рядовым членам команды, поэтому их решение не должно вызывать трудностей. При этом еще одна часть обращений (возможно, около 30%) могут оказаться достойны внимания лучших специалистов службы поддержки независимо от их структурной принадлежности.
Здесь используется группа третьего типа: Backlog Swarm.
Backlog Swarm (Группа работы с накопившимися задачами)
Проводит встречи регулярно, обычно ежедневно.
Основное внимание: решение сложных задач, полученных от команд поддержки продуктовых линеек.
Вторичная задача: замена одиночных экспертов.
Для решения наиболее сложных проблем Backlog Swarm объединяет группы опытных и квалифицированных инженеров, невзирая на географические и структурные границы. Они получают задачи от специалистов на местах, которым теперь запрещено напрямую обращаться к экспертам индивидуально. Вместо этого они должны передавать задачи в соответствующий Backlog Swarm.
Docker в работе. Взгляд на его использование в Badoo (год спустя)
Антон Турецкий (Badoo)
Сегодня я приглашу вас на такую внутреннюю кухню Badoo расскажу о том, нужен ли Docker нам. Вы попробуете сделать выводы для себя, нужен ли он вам. Этой информации на просторах Интернета, соответственно, нет, потому что она вся вот такая – в нашем тесном узком кругу.
В течение доклада я расскажу про самую значимую вещь, которая касается того, с чего надо начинать выполнение любой задачи. Надо решить, зачем вы ее делаете, зачем вы за это беретесь?
Для себя мы на эти вопросы ответили, без проблем у нас не было бы никакого внедрения. Какую-то часть проблем мы решаем. Я выделил основные из них, я расскажу вам о них и о том, как мы с ними справились. В конце я порекламирую нас, какие мы замечательные, как мы любим всякие-разные новые велосипеды, как мы их делаем, смотрим, изобретаем. Я вам их покажу, про них расскажу, вы составите какое-то свое мнение. Итак, поехали!
Самые распространенные возражения
Часто говорят: «Пусть сисадмины дежурят, это их заговор, чтобы я дежурил, а я тут разработкой занимаюсь». Как вы знаете, хороший вопрос — тот, на который есть ответ. А отличный — тот, на который есть слайд. Божественный — тот, на который есть презентация. Вот доклад прошлого года, где в течение часа я разжевываю, почему разработчикам не стоит бояться того, что их посадят дежурить вместо сисадминов.
«Зачем вообще что-то менять, у нас и так все хорошо. И лучшее — враг хорошего». К сожалению, если мы не меняемся, то все плохо, потому что меняется все вокруг нас. Например, история трехлетней давности о том, как Equifax пострадал из-за дырки в безопасности настолько капитально, что CEO пришлось уволиться. Они ничего не делали, а мы не можем себе позволить ничего не делать.
«Колодцы — это хорошо, в них растят настоящих специалистов!». Проблема в том, что, когда мы оптимизируем не в нашем горлышке, то какой бы глубины ни были специалисты, они совершенно бесполезны. Если у нас есть прекрасная разработка, но страдает деплой в продакшн, то какая бы ни была разработка, она совершенно бесполезна.
Элияху Голдратт написал книгу The Goal, которая как раз про оптимизацию процессов. Она вышла в виде комикса, поэтому после того, как мы совсем устали читать 100500 книжек, полистать комикс и поучить оптимизацию очень приятно.
«Регуляции — это ого-го какой тормоз для DevOps, потому что мы не можем сейчас все автоматизировать и дать разработчикам доступ в продакшене, у нас регуляции». Если считать регуляции тем, что надо сертифицировать и проверять каждый релиз — это медленно и нудно. Но на самом деле регуляции не говорят, что надо проверять каждый релиз. Великолепно можно сертифицировать не релиз, а ваш pipeline. И ни один из регуляторов еще не говорил: «Нет, нельзя сертифицировать pipeline» и при помощи этого потерять свои регуляции. Поэтому сертифицируйте свои pipeline, и с регуляцией никаких проблем тоже не будет. А DevOps именно о pipeline и автоматизации и говорит.
«Вот эта история о том, чтобы релизить быстрее — невозможна! Потому что нам нужно гарантировать качество, безопасность и много других вещей. Это все требует времени, мы не можем просто так выкидывать всё в продакшн». Время обычно экономится при использовании какого-то робота или автоматизации. Автоматизируйте все, что надо делать. И на самом деле эта автоматизация помогает не только с тем, что времени будет хватать, а еще с тем, что ее проще будет сертифицировать.
Вася, вооруженный всеми теми знаниями, которые мы предоставили, благополучно трансформировал омский мясокомбинат и стал Chief Information Officer. А потом пошел трансформировать следующую организацию уже сверху. И у Васи дальше было все хорошо. Чего и вам желаем.
Давайте суммируем две ключевые точки доклада.
- Изучайте модель Influence Without Authority, она вам может помочь не только с DevOps-трансформацией, но и с многими другими инициативами в вашей профессиональной жизни.
- Учитесь работать с возражениями.
Заключение
DevOps ставит под сомнение саму суть установившихся консервативных методов работы, объединяя ранее изолированные роли разработчиков и специалистов служб эксплуатации, а также стараясь избавиться от укоренившихся неэффективных практик. Эта философия по большей части (если не полностью) сформировалась в организациях нового поколения, часто не имевших необходимости поддерживать устаревшие, но работающие системы и их пользователей.
Важно отметить, что это было сделано весьма успешно:
Теперь DevOps добрался до традиционных организаций, где в процессе внедрения (зачастую очень болезненного) ему предстоит столкнуться с новыми вызовами. Но для таких компаний это уже не вопрос улучшения, а необходимый шаг в борьбе за выживание. Изменения в форме «творческого разрушения» являются постоянной и реальной угрозой существованию крупных компаний. Только 12% списка Fortune 500 от 1955 года оставались в нем и в 2014.
ИТ-компании должны стараться везде, где только возможно, использовать свежие идеи и постоянно ставить под сомнение консервативные практики.
Swarming-движение начало атаку на модель многоуровневой поддержки, но прогресс в управлении ИТ-сервисами традиционных компаний идет медленно, поскольку он ограничен рамками использования лишь в нескольких дальновидных организациях. Однако близость основных элементов Swarming и DevOps сложно отрицать, и поэтому они имеют схожие проблемы внедрения, решение которых делает проще использование обеих систем.
Таким образом, существует необходимость переосмысления модели многоуровневой поддержки. Новая методология должна использовать преимущества DevOps, сохраняя работоспособность и эффективность в масштабах крупных компаний. Думаю, что Swarming вполне может подойти на эту роль.