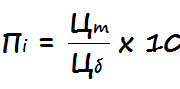Лучшие сервисы анализа текстов сайта: уникальность, seo, орфография
Содержание:
- Нормы тошноты
- Виды тошноты
- Заспамленность текста
- Нормы тошноты
- Что из себя представляет семантический анализ текста?
- TF-IDF и закон Ципфа
- Семантические слова
- Тошнота текста, норма при написании текстов
- 12 Инструментов SEO анализа текстов и структуры сайта
- Проверка текста на тошноту онлайн
- Онлайн-сервисы семантического и SEO-анализа текста
- Норма тошноты в тексте
- Разберем основные параметры оптимизации
- Тошнота текста: зачем ее делать?
- Как убрать лишнюю тошноту текста
- Какой должна быть тошнота текста?
- Тошнота текста: зачем ее делать?
- Как писать тексты без переспама?
- Как создать идеальный текст
- Как измеряют тошнотность текста
- Что такое классическая тошнотность?
Нормы тошноты
Рекомендованные нормы тошноты в различных сервисах:
| Классическая | Академическая | По слову | |
|---|---|---|---|
| Марафон Смарт | — | до 9-10% | до 3% |
| Марафон Пузат (binet.pro) | — | 6-9% | не более 3% |
| Майк | — | 8,5-9,5% | — |
| advego | 7 | 7-9% | — |
| contentmonster | до 7 | — | 3-5% |
| pr-cy | — | до 8% | — |
| 1ps.ru | — | до 10% | — |
| nopyx | не более 3 | не более 10% | не более 2,5% |
- Лично я при составлении ТЗ оперирую показателями по Адвего:
- академическая тошнота документа до 8%;
- тошнота по слову до 3%.
Показателем рекомендованной нормы классической тошноты документа 3-5 практически не пользуюсь, так как он не учитывает общую длину текста.
На самом деле не бывает общих рекомендации по конкретным показателям — в каждой нише «рулят» свои цифры. И проверять нужно экспериментальным путем — посмотрите тошноту своих основных конкурентов в ТОПе и ориентируйтесь на нее.
Как уменьшить тошноту текста при переспаме
- Академическую тошноту текста можно уменьшить:
- увеличив текст;
- уменьшив количество вхождений ключевых слов;
- заменив ключи их синонимами.
Слова-синонимы Яндекс считает соответствующими запросу и подсвечивает их в сниппете.
Нельзя требовать от копирайтера вписать большое количество ключей в маленьком тексте. Опытные копирайтеры практически никогда не высчитывают ни частотность, ни тошноту. Они придерживаются допустимых показателей на уровне интуиции.
Писать нужно для людей, если им легко и интересно читать ваши тексты, значит, с тошнотой в статьях – все в порядке.
Виды тошноты
Выделяют два типа тошнотности (заспамленности):
- Классическая. Зависит от количества употреблений значимых слов в тексте. Высчитывается по формуле: «квадратный корень от общего числа добавлений». То есть, если слово «тошнота» в тексте появилось 25 раз, то показатель равен 5. Заказчики редко предлагают копирайтерам ориентироваться непосредственно на классическую тошнотность и больше доверять альтернативной статистике.
- Академическая. Отношение количества употреблений значимых слов к объему текста. Высчитывается в процентах по формуле: «количество слов * 100 / на объем статьи». Если подставить значения, то результат следующий: слово «Тошнотность» встречается 7 раз на 5000 символов, то академическая заспамленность равна 14%.

Заспамленность текста
Высокая доля повторений в статье создается при переоптимизации, когда на фоне ограниченного объема слов в ней встречаются сплошные ключи, перенасыщение которыми поисковые системы принимают за СПАМ и ограничивают поисковый трафик.
Добиться оптимизации материала непросто, в частности, когда речь идет об узкоспециализированной направленности заметки, когда трудно подобрать синонимы для ключевых слов.
Заспамленность, как уже отмечалось, тесно связана с термином «тошнота текста» и их допустимые величины могут резко отличаться для заметок разной направленности.
Поисковые системы в большинстве случаев считают документ оптимизированным и релевантным ключевым словам, когда их объем колеблется в диапазоне 30-60%, превышение которого считается заспамленностью текста, так как он включает не связанные фразы, предложения и трудно поддается осмыслению.
Если же ключевых слов в статье меньше 30%, то поисковики их попросту могут не заметить.
Дополнительно следует придерживаться также правила, чтобы ключевые слова и фразы не встречались в двух предложениях подряд, а распределялись равномерно по всему объему заметки и встречались в разных вхождениях. Промежуток между ключевиками в 300-400 символов считается оптимальным.
Документы, содержащие малый объем материала, должны подвергаться проверке более тщательно, потому что добавленные искусственно ключевые фразы и слова сразу же замечаются роботами поисковиков и могут стать «камнем преткновения».
Неплохим подспорьем в работе копирайтеров или рерайтеров при проверке заспамленности текста служит бесплатный сервис text.ru.
Поисковыми системами критерий тошноты используется с 2006 года, когда резко изменился подход поисковиков к контенту и алгоритмы ранжирования начали учитывать, как плотность ключевых слов, так и общее количество повторений фраз.
Если до этого заметка, нашпигованная ключевыми словами и фразами, например, через каждое предложение, оказывалась на вершине ТОПа поисковых систем, то сейчас следует писать для людей понятно, кратко и, чтобы материал полностью отвечал на запрос пользователя.
С развитие новых сервисов критерий тошнотности не столь актуален, но он не исключен поисковыми системами, поэтому превышение предельных значений чревато плачевными последствиями.
При оптимизации документа различают классическую и академическую тошноту текста.
Нормы тошноты
Понятия нормы тошноты размыты и даже копирайтер со стажем точно не может сказать, какой текст считается идеальным и самое главное – будет расценен поисковой системой на высшем уровне. Если сравнить работу нескольких проверочных программ, то там единства тоже не обнаружить – каждая из них выдает свои параметры.
Например, норма в процентах для Адвего от 7 до 9% академической тошноты, а Text.ru считает правильным показатель до 7%. Такой же стратегии придерживается и программа Miratex. И даже если слово употреблялось минимальное количество раз, то все равно можно лишь приблизиться к нижней границе, но не достичь ее.

Нормы тошноты текста
Чтобы понять, как писать с низкой тошнотой, почитайте информацию о теме, по которой пишете работу. После ознакомления появятся идеи, какими аналогами заменить повторяющиеся слова без потери смысла. Это первый шаг к тому, чтобы не повторяться и создать живой, интересный контент не для поисковой машины, а для целевого контингента вашего сайта.
Что из себя представляет семантический анализ текста?
После того, как вы вставили свой текст в специальное окно, сайт Advego анализирует его. Результаты семантического анализа текста всегда представляют собой четыре таблицы: «Статистика текста», «Семантическое ядро», «Слова» и «Стоп-слова». Давайте разберемся с каждой из них.
Просто угадай на Binarium куда пойдет курс Вверх или Вниз. Сделай правильный прогноз и получи до 90% чистой прибыли от ставки. Можно потренироваться на бесплатном демонстрационном счете.
2.1 Статистика текста
Данная таблица выглядит, как два столбца под названием «Наименование показателя» и «Значение». В первом, соответственно, идет перечисление тех показателей, анализ которых проводился. А во втором – их численное или процентное соотношение к тексту.
Первый столбец содержит в себе следующие наименования показателей:
- Количество символов (определяется общее число символов в статье).
- Количество символов без пробелов (определяется число символов в статье, за исключением пробелов).
- Количество слов (общий подсчет слов в тексте, кстати предлоги тоже включаются в этот показатель).
- Количество уникальных слов (в данном случае Advego суммирует все слова, которые присутствуют в тексте хотя бы единожды, но их повторения не засчитываются сервисом).
- Количество значимых слов (а в этом случае ведется подсчет всех существительных, несущих хоть какую-то смысловую нагрузку).
- Количество стоп-слов (сюда входят абсолютно все предлоги, содержащиеся в тексте, а также наиболее популярные в Интернете слова).
- Вода (в сфере копирайтинга «водностью» называют процентное соотношение незначимых слов и стоп-слов текста к значимым и несущим смысловую нагрузку. Слишком высокий процент водности (от 65 %) грозит сайту снижением в топ-выдаче поисковых запросов. Ни один текст не обходится без содержания в нем «воды», поэтому особо заморачиваться на этот счет копирайтерам не стоит. Считается, что нормальное содержание «воды» в тексте – это 40-60%).
- Количество грамматических ошибок (сервис Advego подсчитывает общее количество ошибок в статье, включая и те слова, которых нет в словаре. В идеале этот показатель должен быть равен 0).
- Классическая тошнота (классической тошнотой называют количество повторяемых одних и тех же слов в статье. Самым оптимальным вариантом для объемной статьи является число «7» напротив показателя «Классическая тошнота», так как чрезмерная заспамленность текста ведет к его упадку в рейтинге поисковых запросов).
- Академическая тошнота (под академической тошнотой понимается количество разных слов, повторяющихся в тексте).
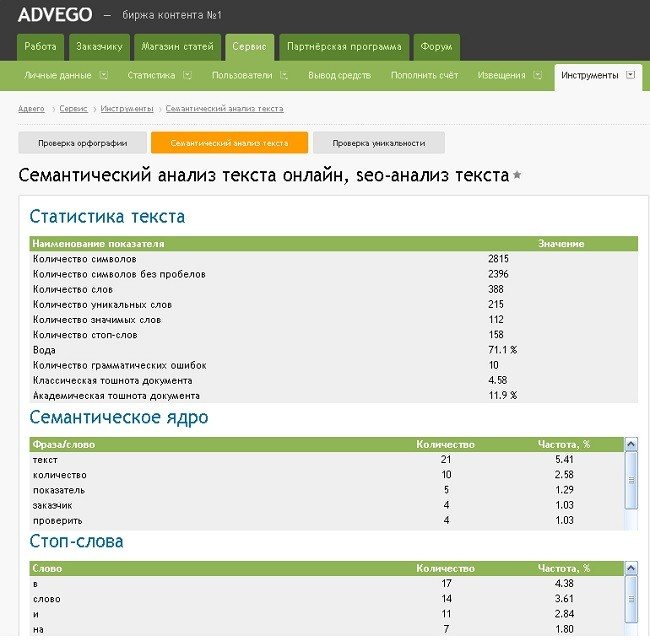
2.2 Семантическое ядро
Под этим понятием подразумеваются наличие слов и словосочетаний в тексте, с помощью которых пользователи Интернета будут делать поисковой запрос. На Advego семантическое ядро представляет собой таблицу с тремя колонками:
- «Фраза/слово»: перечисляются все поисковые слова;
- «Количество»: подсчитывается количество повторений каждого поискового слова и словосочетания;
- «Частота, %»: процентное соотношение повторений поисковых слов и фраз в тексте.
2.3 Слова
В данном случае, под словами подразумевают все уникальные слова в тексте. Их пересчет ведется также в таблице с такими колонками, как «Слово», «Количество», «Частота, %», значение которых полностью идентично семантическому ядру.
2.4 Стоп-слова
Как уже писалось выше, стоп-слова представляют собой абсолютно незначимые слова в тексте, то есть предлоги и самые популярные поисковые слова. Таблица с количеством стоп-слов полностью идентична таблице с количеством уникальных слов.
TF-IDF и закон Ципфа

Проверка по закону Ципфа – это метод распределения частоты слов естественного языка: если все слова языка (или просто достаточно длинного текста) упорядочить по убыванию частоты их использования, то частота n-го слова в таком списке окажется приблизительно обратно пропорциональной его порядковому номеру n (так называемому рангу этого слова). Например, второе по используемости слово встречается примерно в два раза реже, чем первое, третье – в три раза реже, чем первое, и так далее. Наиболее часто используемые 18% слов (приблизительно) составляют более 80% объема всего текста.
Самые популярные слова будут отображаться в большинстве документов. В результате такие слова усложняют подбор текстов, представленных с помощью модели мешка слов. Кроме того, самые популярные слова часто являются функциональными словами без смыслового значения. Они не несут в себе смысл текста.
10 самых популярных слов в русском языке:
1. и
2. в
3. не
4. на
5. я
6. быть
7. он
8. с
9. что
10. а
Мы можем применить статистическую меру TF-IDF (частота слова – обратная частота документа), чтобы уменьшить вес слов, которые часто используются в тексте и не несут в себе смысловой нагрузки. Показатель TF-IDF рассчитывается по следующей формуле:
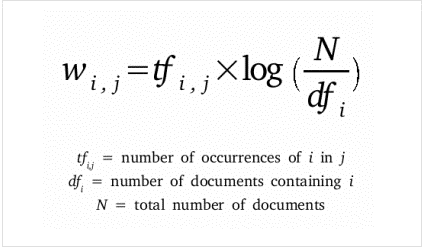
- tfi,j– частота слова в тексте,
- dfj– количество документов, содержащих текст с данным словом,
- N – общее количество документов.
В таблице ниже приведены значения IDF для некоторых слов в пьесах Шекспира, начиная от самых информативных слов, которые встречаются только в одной пьесе (например, «Ромео»), до тех, которые настолько распространены, что они полностью не дискриминационные, поскольку встречаются во всех 37 пьесах. Такие как «хороший» или «сладкий».
IDF самых распространенных слов равен 0, в результате их частоты в модели мешка слов также будут равны 0. Частоты редких слов будут наоборот увеличены.
|
Слово |
DF |
IDF |
|
Ромео |
1 |
1,57 |
|
салат |
2 |
1,27 |
|
Фальстаф |
4 |
0,967 |
|
лес |
12 |
0,489 |
|
боевой |
21 |
0,074 |
|
дурачить |
36 |
0,012 |
|
хорошо |
37 |
|
|
милая |
37 |
Семантические слова
Семантический поиск стал ключевым словом в SEO сообществе с 2013 года. Семантический поиск — это поиск со смыслом, в отличие от лексического поиска, где поисковая система ищет буквальные совпадения слов или вариантов запроса, не понимая общего значения запроса.
Приведем простой пример. Вводим запрос в Яндекс или Google – пьяный на новый год перепутал квартиру фильм. Результаты выдачи можете увидеть на фото.

Вы же сразу поняли, о каком фильме идет речь? Как мы видим, поисковая система отлично справилась с задачей. Несмотря на то, что в нашем запросе нет слов ирония / судьба / с легким паром, в выдаче мы видим «Иронию судьбы».
Но как поисковая система может понять значение слова или смысл поискового запроса? Или как мы должны указать значение слова, чтобы компьютерная программа могла понять и практически использовать его в выдаче документов?
Ключевой концепцией, которая помогает ответить на эти вопросы, является дистрибутивный анализ. Она была впервые сформулирована еще в 1950-х годах. Лингвисты заметили, что слова с похожим значением имеют тенденцию встречаться в одной и той же среде (то есть рядом с одними и теми же словами), причем количество различий в значении между двумя словами примерно соответствует разнице в их LSI-фразе.
Вот простой пример. Допустим, вы сталкиваетесь со следующими предложениями, при этом не зная, что такое лангустин:
Лангустины считаются деликатесом.
У лангустинов белое мясо в хвосте и на теле, сочное, слегка сладкое и постное.
При выборе лангустинов мы обращаем внимание на полупрозрачный оранжевый цвет.
Также вы определенно сталкиваетесь со следующим, так как большинство читателей знают, что такое креветка:
- Креветки – это лакомство, которое хорошо сочетается с белым вином и соусом.
- Нежное мясо креветки можно добавить к пасте.
- При варке креветки меняют свой цвет на красный.
Тот факт, что лангустин встречается с такими словами, как деликатес, мясо и макароны, может указывать на то, что он является своего рода съедобным ракообразным, в чем-то похожим на креветок. Таким образом, можно определить слово по среде, в которой оно встречается и по множеству контекстов.
Как мы можем преобразовать эти наблюдения в нечто значимое для компьютерной программы? Можно построить модель, похожую на мешок слов. Однако вместо документов мы обозначим столбцы с помощью слов. Достаточно распространено использование небольших фраз в контексте целевого слова, но не более четырех слов. В этом случае каждая ячейка в модели обозначает количество, сколько раз слово встречается в контекстной фразе (например, плюс-минус четыре слова). Давайте рассмотрим эти контекстные фразы. В таблице ниже пример из книги Даниэля Джурафски и Джеймса Мартина «Обработка речи и языка».
Контекст
Ключевое слово
Контекст
сахар, нарезанный лимон, столовая ложка
абрикос
варенье, щепотка каждого из
их удовольствие
Она осторожно взяла пробу
ананас
и другой фрукт, вкус которого она сравнила
хорошо подходит для программирования на цифровом
компьютер
В поиске оптимальной R-стадии политики из
с целью сбора данных и
информация
необходимо для исследования, разрешенного в
Для каждого слова в соседних колонках мы указываем тематические слова из текста, где оно используется. В результате получаем матрицу совпадения слов
Обратите внимание, что «цифровые» и «информационные» контекстные слова больше похожи друг на друга, чем на «абрикосовые». Количество слов может быть заменено другими показателями
Например, показатель взаимной информации.
|
трубкозуб |
… |
компьютер |
данные |
зажимать |
результат |
сахар |
… |
|
|
абрикос |
… |
1 |
1 |
… |
||||
|
ананас |
… |
1 |
1 |
… |
||||
|
цифровой |
… |
2 |
1 |
1 |
… |
|||
|
информация |
… |
1 |
6 |
4 |
… |
Каждое слово и его семантическое значение представлены вектором. Семантические свойства каждого слова определяются его соседями, то есть типичными контекстами, в которых оно встречается. Такая модель может легко уловить синонимию и родственность слов. Векторы двух одинаковых слов будут проходить рядом. Векторы слов, которые появляются в одном и том же тематическом поле, будут образовывать кластеры.
В семантическом поиске нет магии. Концептуальное различие заключается в том, что слова представляются в виде векторных вложений, а не лексических элементов.

Тошнота текста, норма при написании текстов
Какова норма тошноты текста? Приемлемая частота засламленности текста не должна превышать 15-50%. Если текст написан на 3000 знаков, то 15% тоншоты для текста будет нормой. Если будет текст по объему больше, например, 5000-9000 знаков, значит 50% тошноты нормальный показатель. Обычно этих показателей придерживаются копирайтеры на биржах фриланса и блогеры.
Что такое академическая тошнота текста
Существует два типа тошноты текста академическая и классическая. В этом разделе статьи мы рассмотрим, что такое академическая тошнота текста.
Что такое академическая тошнота? Она определяет процент плотности ключевых слов в ваших статьях. Если в статье будет много ключевых запросов в зависимости от объема текста, то она считается переоптимизированной.
После проверки такого текста поисковым роботом, статья перестанет отображаться в поиске Яндекса или Гугла. Затем, у ресурса и статьи будут понижаться позиции в Интернете.
Рассчитывается академическая тошнота текста следующим образом: Если объем вашей статьи на 2000 символов и ключевой запрос находится в тексте 20 раз, то данная тошнота равняется 4%. Норма академической тошноты – 7-9%.
Что такое классическая тошнота
Рассмотрим еще один вид тошноты текста – классическую тошноту. Данный параметр текста принято называть квадратным корнем, который высчитывает частоту тошноты из одного слова в тексте. К примеру, в нашей статье встречается слово работа 20 раз. Квадратный корень из 20 будет равен 4,5% классической тошноты.
Норма классической тошноты должна быть 2,6-7%.
12 Инструментов SEO анализа текстов и структуры сайта
Онлайн инструменты проверок оптимизации текстов и структуры сайта
Нет SEO инструментов анализирующих только тошноту текста или только его водность. Эти анализы, обычно, входит в комплексные инструменты проверки текстов.
Text.ru (Текст. РФ)
Инструмент с лучшим алгоритмом проверки оптимизации текстов. Анализ проводится по 7 позициям, включая уникальность, орфография, SEO-анализ (вода, заспаменость, кол-во символов, слов). Делается полный анализ по ключевым словам и фразам с разделением их по группам и указанием частоты повторяемости.
Адрес инструмента: https://text.ru/.
Istio.com
SEO-инструмент Istio.com проводит комплексный SEO анализ текстов, исключая уникальность. Покажет параметры текста: длина текста, водность, выделит десятку наиболее частых слов (не фраз), показывает карту текста по встречаемости слов.
Адрес Инструмента: http://istio.com/rus/text/analyz/
Advego.ru
Совсем недавно, инструмент Advego.ru анализа тестов, работал как программа, которую нужно было установить на свой компьютер. Сейчас появился онлайн режим проверок. Advego проверяет уникальность теста и делает весь стандартный набор семантических SEO проверок.
Кроме уникальности, Адвего покажет:
- Кол-во символов, уникальных и значимых слов, стоп-слов;
- Водность %;
- Классическая и академическая тошнота текста;
- Покажет семантическое ядро текста, частоту повторяющихся слов и фраз.
Адрес: https://advego.ru/text/seo/
Pr-cy.ru Analysis content
Интересный инструмент, показывающий вес home page сайта, релевантность title, % релевантности ключей (keywords) ко всему тексту. Кроме этого, на релевантность проверяются слова в тегах H1.
Адрес: https://pr-cy.ru/analysis_content
Проверка веса слов
Для SEO анализа текстов и структуры есть интересный инструмент, который делает анализ веса слов в поисковой базе Яндекс (2010 год). Работа инструмента основана на утверждении: алгоритм поисковика в поиске дает приоритет относительно редким словам и слабо учитывает частотные слова.
Адрес: http://tools.promosite.ru/old/weight.php
Проверка текста на тошноту онлайн
Самостоятельно сидеть пару часов, высчитывать показатели тошноты документа вообще не резон, нет смысла. Для облегчения труда вебмастера, копирайтера существует немало онлайн-сервисов, позволяющих выполнить анализ статьи на заспамленность за секунды. Вот некоторые из них.
Advego
Самый популярный сервис по семантическому анализу текста. Результат выдаётся реально через несколько секунд. Ограничений по количеству проверок в сутки нет. Проверка происходит на этой странице.
Вставляете в поле текст и жмите проверить. Помимо тошнотности увидите основную статистику.

Это показатели одной из статей на блоге. Академическая и классическая тошнота находятся в пределах нормы. Значит, переспама нет. Во второй таблице показано семантическое ядро. Проверьте, те ли слова и выражения на первых местах.
В четвёртой таблице указаны стоп-слова. От многих из них можно избавиться без вреда для статьи. Текст станет более читабелен.
Text

Тошнота отображается как Заспамленность. Сервис использует собственный алгоритм вычисления поэтому и значения далеки от адвеговских. Проверяю ту же страницу что и Адвего. Заспамленность равна 53%.

Для TEXTa это нормально. От 30 до 60 % текст считается SEO оптимизированным, отвечающим релевантным ключевым словам.
Немного отойду от темы переспама в статьях. Главная функция Texta и его преимущество — проверка статьи на уникальность. На скриншоте заметили уникальность проверяемой статьи составила 0,39%? Указаны два сайта: мой и ещё один. Вывод: какой-то муд.к скопипастил статью и выложил у себя на сайте без предупреждения. Внизу страницы проверки на уникальность нашелся ещё один.
Буду обращаться в Google и Яндекс с жалобой на копипастеров. Желающих взять чужое всегда хватало. Надо думать о безопасности материалов. В дальнейшем напишу о предпринятых мерах и результатах.
Статью для примера взял случайно, крайне удачно. Так бы не знал. Следует проверить весь сайт на уникальность.
Miratext
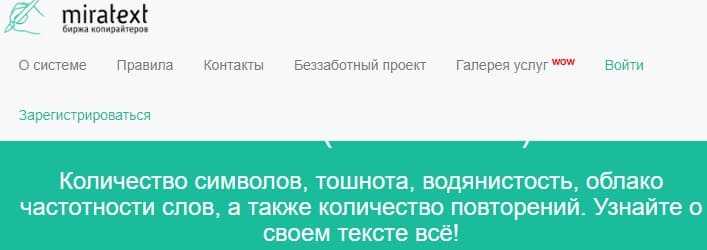
Вначале общие данные о статье. Затем по разделам касающиеся семантики и тошноты текста.
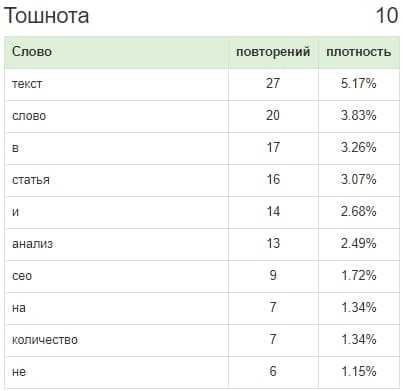
Есть интересная диаграмма анализа текста по закону Ципфа,

рекомендации по улучшению. Право автора пользоваться или нет.
Что касается тошноты текста Miratext рекомендует ниже 3,5%. В статье значение превышено. Меня это сильно не заботит. Привык работать с Адвего и TEXTом, ориентируюсь на их данные.
Есть ещё PR-CY, Istio, они подобны предыдущему.
Вывод
Перед публикацией на сайт обязательно следует проверить текст на тошноту. За значительное превышение, за переспам сайт может попасть под фильтр поисковых систем. Если вы копирайтер — будете дорабатывать статью, добиваясь требуемых заказчиком требований.
Как и в любом деле нужна практика. Возьмите за правило писать каждый день, даже короткие статьи по 300 слов, со временем тексты будут получаться оптимизированные и без переспама.
И главное — тексты надо писать не для поискового робота, а для пользователя.
Удачи Всем! Пишите классные статьи и выходите в ТОП.
Онлайн-сервисы семантического и SEO-анализа текста
Advego.com. Семантический анализ от биржи контента Адвего — один из самых популярных сервисов у SEO-специалистов. Он бесплатен, доступен всем незарегистрированным и зарегистрированным пользователям. Показывает:
- Академическую тошноту;
- Классическую тошноту;
- Количество стоп-слов;
- Показатель «воды»;
- И другие менее значимые параметры.

Istio.com. Это — сервис, разработанный специально для семантического анализа текста. Доступен всем, регистрация не обязательна. Не требует оплаты подписки. Показывает:
- Показатель водности;
- Тошноту;
- Топ-10 самых используемых слов;
- Тематику текста;
- Другие параметры.
Miratext.ru. Это — еще один сервис от биржи копирайтинга. Тоже бесплатный, доступный зарегистрированным и незарегистрированным пользователям. Показывает:
- Тошноту;
- «Водянистость»;
- Качество по закону Ципфа;
- Облако частотности слов;
- Другие менее значимые цифры.
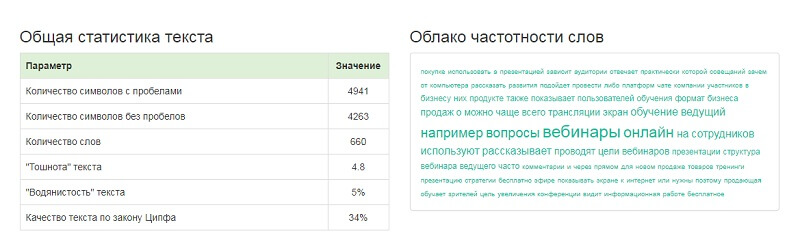
Внимание! У каждого сервиса свой алгоритм, поэтому единых цифр, на которые стоит ориентироваться, нет. Например, наш текст показал тошноту 4,12/8,7%, 4,79% и 4,8% на трех разных сервисах
Цифры похожи, но не совпадают. Поэтому обязательно читайте описание самого сервиса проверки и ориентируйтесь на рекомендованные им показатели.
Норма тошноты в тексте
Переспам ключей или аномально частое повторение других слов понижает читабельность текста и делает его неприглядным в глазах поисковиков (за это даже можно получить фильтр на сайт и лишиться показов).
Слишком низкий процент тошноты указывает на низкую полезность текста. И если людям такая работа еще может понравиться, то поисковики, скорее всего, не заметят такой материал. Штраф за это не дают, но и показы тоже не светят – поисковик определяет такой материал как нерелевантный поисковым запросам, бесполезный для людей.
Какова же норма тошноты текста? Для каждого вида свои значения:
- академическая – 6%–9%;
- классическая – 7%;
- по слову – от 2,5% до 3%.
Эти показатели актуальны для сервиса проверки Адвего, на других площадках они могут отличаться. В прочем, давайте разберем это подробнее.
Разберем основные параметры оптимизации
В результате разберем следующие основные параметры оптимизации, на которые нужно обратить внимание:
- Знаки без пробелов, с ними, различные ошибки. Здесь, я думаю, сложности возникнуть не должно.
- Наличие уникальных слов. Эти слова могут встречаться в статье всего раз. Если число будет повторяться более двух раз, то уже считается неуникальным.
- Значимые слова. Они определяют полезность содержимого. Учитываются имена существительные.
- Стоп-слова. Как правило, они не подразумевают смысла. К ним относятся: так, вот, или, на, как и другие. Они просто служат для связки словосочетаний в предложении.
- «Вода». Это соотношение значимых слов к общему объему, то есть они не значат информационную ценность. Средний показатель в этом случае считается около 60-75%. Для некоторых распространенных тем этот показатель может быть и несколько больше, это тоже нужно учитывать.
Тошнота текста: зачем ее делать?
Нужна ли проверка по тошноте? Разберемся. Она бывает:
- Академической.
- Классической.
Академическая выдает полезность контента. Чем больше будет повторяться одинаковых слов, тем выше этот фактор. Нормой считается 10%.
Классическая тошнота определяет заспамленность материала. В норме считается около 7%. Если данный коэффициент будет больше, то статью достаточно сложно увеличить в поиске и есть вероятность попасть в фильтры
На данный параметр я обычно обращаю главное внимание
Проверка контента на тошнотность в Адвего является незаменимой для сео-копирайтера. Тем более это делать легко и совсем не сложно, как вы заметили.
Как убрать лишнюю тошноту текста
После того, как анализ выполнен, переходите к следующему этапу работы — снижать или повышать показатель; как снизить тошноту по Адвего — расскажем далее.
Если вы заметили, что уровень тошноты получился высокий или низкий, это будет оказывать влияние на SEO. При этом опытным путем было установлено, что распространенная причина понижения рейтинга контента — академическая, а не классическая тошнота
По этой причине большинство оптимизаторов уделяют ей основное внимание
Как правило, пользователи программы задают следующий вопрос по использованию Адвего: можно ли исправлять показатели прямо на сайте после проверки? К сожалению, такой возможности не предусмотрено. Вам придется редактировать текст, а затем, когда вы это сделали, проверять его снова.
Как уменьшить классическую и академическую тошноту
Теперь рассмотрим, как уменьшить академическую тошноту. Поскольку ее показатель — это отношение количества вхождений ключевых слов к объему всего текста, пути для редактирования очевидны: либо уменьшать содержание «ключей», либо увеличивать объем статьи.
Второй способ, по многим причинам, является менее приоритетным. Во-первых, объем — тоже важный параметр для SEO-оптимизации, и его увеличение может негативно отразиться на рейтинге статьи. Во-вторых, это более трудоемкий процесс, нежели простое избавление текста от нескольких «лишних» слов.
Для этого посмотрите, какие слова и фразы – самые повторяемые, и удалите их из текста. Также можно заменить их синонимами, или перестроить предложения таким образом, чтобы они «выпадали» из них.
Теперь о том, как поднять, или увеличить этот показатель; чтобы повысить академическую тошноту, добавьте ключевые слова в статью таким образом, чтобы количество их вхождений возросло.

Что касается классической, то поднимать ее специально не требуется для оптимизации. А вот понизить ее можно, удалив несколько вхождений самого популярного слова, а также очистив статью от «стоп-слов», которые при анализе сервисом Адвего будут приведены в специальной таблице.
Какой должна быть тошнота текста?
В каждом отдельном случае, этот показатель разный. Однако для:
- академической следует придерживаться диапазона от 4 до 7 %
- классической — не более 2,5
Вы наверное уже поняли, что слишком большой или слишком низкий её уровень может привести как к переспамленности, так и к фильтру со стороны поисковиков, да и сам материал не будет нести смысловой нагрузки для читателей.
Гармоничное включение ключевых слов поможет избежать ошибок в оформлении статей. Но если после написания этот показатель высокий, необходимо провести анализ и выяснить, какие слова больше всего повторяются, затем сократить их или заменить синонимами. Есть специальные сервисы, которые помогут подобрать синонимы, если вам сложно это придумать. Они особенно помогают тем, для кого русский язык не является родным.
Тошнота текста: зачем ее делать?
Нужна ли проверка по тошноте? Разберемся. Она бывает:
- Академической.
- Классической.
Академическая выдает полезность контента. Чем больше будет повторяться одинаковых слов, тем выше этот фактор. Нормой считается 10%.
Классическая тошнота определяет заспамленность материала. В норме считается около 7%. Если данный коэффициент будет больше, то статью достаточно сложно увеличить в поиске и есть вероятность попасть в фильтры
На данный параметр я обычно обращаю главное внимание
Проверка контента на тошнотность в Адвего является незаменимой для сео-копирайтера. Тем более это делать легко и совсем не сложно, как вы заметили.
Как писать тексты без переспама?
Современные сервисы анализа тошноты текста помогают копирайтерам доводить статьи до идеала. Но куда лучше и легче сразу писать контент, соответствующий принятым нормам. Это довольно просто, достаточно следовать простым правилам.
- Прежде всего, контролируйте повторяемость слов.
- Заканчивая писать каждое четвертое предложение, перепроверьте, не повторяете ли вы фразы, не употребляете ли ненужные и лишние стоп-слова, не допускаете ли тавтологию.
- Не пишите одну и ту же статью больше двух часов. Спустя столько времени вы перестанете замечать повторения. Отвлекитесь, сделайте перерыв.
- На досуге читайте литературу – это поможет пополнить свой словарный запас.
Как создать идеальный текст
При написании статей важно не только ставить задачу, как повысить показатели, а и сочетать их со здравым смыслом. Оптимальной является тошнота до 10%
Уложиться в нее просто, если писать живым языком, с применением синонимов, местоимений и других приемов по замене слова.
При заспамленности выше 10 учитывайте направленность текста. Если это медицинская или техническая статья, то здесь трудно подобрать синонимы ко всем частым словам. Во многих случаях понижение заспамленности ведет к ухудшение смысловой нагрузки, появлению существенных ошибок, о которых автор работы может и не подозревать. Стоит ли рисковать ради нескольких процентов качеством контента и своей репутацией?
Учтите, что современные поисковики учитывают не только цифровые параметры, но и тематику контента. Поэтому узкоспециальный текст при повышенном проценте спамности вполне может занять ТОПовую позицию.
Как измеряют тошнотность текста
Различают несколько разновидностей:
Классическая тошнота — числовой показатель, его считают как квадратный корень из частоты упоминания слова в тексте. К примеру, если слово встречается в тексте 25 раз, показатель классической тошноты — 5. Максимально допустимым показателем считают 7, выше этого — спам.
Показатель не может быть меньше 2,64, поэтому даже если слово встречается меньше 7 раз, все равно 7 упоминаний — крайнее число для подсчетов. Метод использовать неудобно, поскольку объем текста не берут в расчет.
Академическая тошнота — процентный показатель, тоже зависит от количества повторов слова в тексте. Считают как отношение числа повторов в тексте к количеству всех слов. Учитывают не только точное вхождение ключа, но и другие морфологические формы. К примеру, если в тексте 600 слов, а ключ употребляется 15 раз, то 15/600*100=2,5%.
Допустимым считают 4-6%, от 8% начинается высокий уровень тошноты, нужно уменьшать частотность употребления ключа.
Как регулировать тошноту
В оптимизированном тексте должно быть достаточно ключевых слов. Обычно копирайтеру составляют техническое задание, ориентируясь на оптимизацию
конкурентов из топа: вычисляют оптимальную длину SEO-текста, ключи и их количество, не выходя за рамки рекомендуемых норм.
Если процент тошноты слишком большой, нужно либо увеличить текст, чтобы количество нужных слов приходилось на больший массив текста, либо перефразировать и удалить часть ключей.
Если ключей недостает, можно сделать также, но в обратную сторону: укоротить текст или добавить ключевых слов.
Ориентируйтесь на здравый смысл, правила русского языка и естественность фраз. Стремление достичь точного процента только увеличит время работы над текстом и может ухудшить его качество.
Что такое классическая тошнотность?
Под классической тошнотностью понимается содержание одного и того же слова в документе. В качестве примера приведём небольшой отрывок:
Сковорода имеет защитное покрытие из тефлона. В процессе нагрева тефлон не выделяет вредных веществ ни в еду, ни в атмосферу кухни. Тефлон препятствует прилипанию продуктов, также тефлон позволяет снизить количество масла. Посуда с тефлоном занимает примерно 99% рынка – это сковороды с тефлоном, сотейники с тефлоном и казаны с тефлоном.
Глядя невооружённым взглядом, можно заметить, что повторяемость слова тефлон просто зашкаливающее. Проверка в Адвего показывает тошнотность 2,83%. При этом частота повторения слова тефлон составляет 16,67% – в рамках SEO это явный перебор. Текст с высоким повторением одного и тот же слова не сможет поднять страницу сайта на первые места поисковых систем.