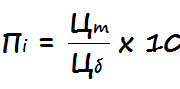Key collector: полное практическое руководство
Содержание:
- Общая настройка Кей Коллектора
- Что такое Key Collector?
- Процесс парсинга в Кей Коллекторе
- Сбор семантики в Key Collector
- Сбор семантики
- Борьба с погрешностями и операторы поиска
- Почему лучше не участвовать в складчине
- Сбор частотностей
- Редактирование ячеек
- Как установить программу на компьютер
- Выполнение поиска и работа с результатами
- Преимущества сервиса от Моаб очевидны:
- Сортировка и фильтрация данных
- Другие функции Кей Коллектора полезные для директолога:
- Удаление и сокрытие групп
- Быстрый сбор СЯ
- Заключение
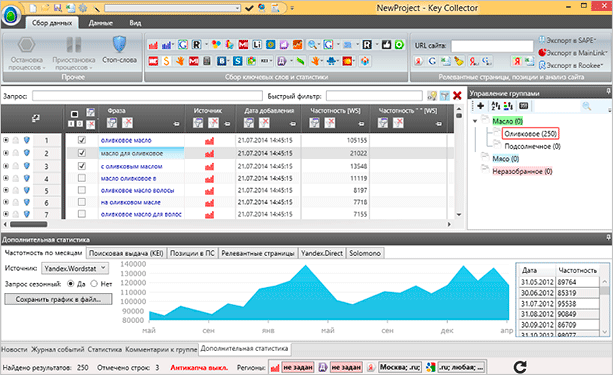
Общая настройка Кей Коллектора
Для работы с вордстатом понадобиться: здесь все просто, нужно отдельно зарегистрировать яндекс почту и создать там тестовую рекламную кампанию, можно с одним объявлением, можно просто черновую (без прохождения модерации и пополнения бюджета). В программе просто прописываем логин и пароль от почты и все работает.
Для работы с гугл планером понадобиться: зарегистрировать новый аккаунт в гугл адвордс. В обязательном порядке скачать последнюю версию браузера internet explorer и зайдя исключительно через данный браузер, также создать тестовую рекламную кампанию (без бюджета и активности). Главное заполнить все настройки пользователя — указать язык и местоположение. Фокус заключается в том, что без данных манипуляций, использовать гугл планер не получиться.
Переходим непосредственно к настройкам:

Заходим в настройки программы во вкладку Яндекс Вордстат», где выставляем следующие параметры:
— глубина парсинга — 0. Выставляя такое значение, вы будите получать обычный парсинг, но программа может автоматом парсить и в глубину, т.е. спарсив ключевые слова, она может парсить то, что уже спарсила, разбивая ключевые слова на более конкретные ключевые слова. Смысла глубокого парсинга нет, так как система будет парсить дубли, а не уникальные ключевые слова, и даже без глубокого парсинга мы все равно будем по нему показываться, так как используем основную маску. Если просто — глубокий парсинг делать не надо, выставляем значение ноль.
— парсить страницы, здесь выставляем стандартное значение — 40.
— добавлять в таблицу фразы с частотами от 1 до 99999999999. Здесь вы указываете какую частотность вы хотите видеть с парсенных ключевых слов. Есть директологи, которые не парсят все доскональна, а работают с ключевыми словами, которые имеют частотность от 10 и выше. Я же советую вам парсить все и начинать с 1. При таком подходе у вас будет самое полное семантическое ядро, а если вы решите, что такие ключевые слова вам не нужно, то уже после парсинга, можно при помощи фильтра выделить такие ключи и удалить.
— не снимать частоты для фраз меньше или равной 0. Логика проста, нам не нужно пустые ключевые слова, которые не будут приносить трафик, поэтому такие не ищем.
— количество потоков. Если вы используете одну почту от яндекс директа, то можете смело выставлять сразу 2 потока, и таким образом программа будет работать в два раза быстрее. И если вы не используете прокси сервера, то не убираем галочку «Использовать основной IP адрес».

Далее заходим во вкладку «Яндекс Директ», где указываем адреса свои электронных почт от яндекса и пароли от них. Достаточно указать 1-2 почты.

Во вкладке «Гугл Адвордс» указываем доступы от гугл адвордс (что логично).
Собственно, это все стандартные настройки, после которых заработает кей коллектор.
Что такое Key Collector?
Кей Коллектор – это платная утилита, которая повсеместно используется сеошниками и маркетологами. Суть ее состоит в почти полной автоматизации сбора семантического ядра. Приложение тесно интегрировано с Яндекс Директом, Вордстатом, гугловскими сервисами и прочими инструментами, которые поодиночке не выглядят такими практичными.
То есть Key Collector объединяет в себе несколько сервисов, интегрируя их возможности. Это позволяет людям легко и просто парсить запросы с того же Вордстата или Директа, в последствии превращая их во вполне себе обоснованное семантическое ядро.
Как я уже сказал, чтобы пользоваться программой, ее придется купить. Разработчики очень сильно заботятся о сохранении лицензии, поэтому каждая отдельная программа привязывается к одному персональному компьютеру с помощью идентификатора жесткого диска. Следовательно, вы не сможете скачать приложение, чтобы использовать его на нескольких машинах – 1 лицензия для 1 компьютера.
В интернете, конечно, есть взломанные версии, которые якобы предоставляют те же возможности, что и оригинал. Однако стоит учитывать, что через пиратское ПО очень часто распространяются вирусы
Если уж вы не хотите покупать Коллектор, то я бы рекомендовал вам обратить внимание на СловоЁб. Это бесплатное приложение от тех же разработчиков, которое представляет собой урезанный вариант Коллектора
Теперь давайте более подробно рассмотрим возможности программы. Итак, как заявляют разработчики, с помощью Key Collector мы сможем составить более точное семантическое ядро, не прибегая к помощи сторонних специалистов. Нам лишь нужно правильно настроить все параметры и познать некоторые азы.
Надо сказать, что Key Collector не работает с готовыми базами данных, которые требуют постоянные обновления. Он парсит всю информацию в реальном времени через интернет, подключаясь ко все тем же сервисам: Вордстат, Яндекс Директ, Гугл Адвордс и прочим. Такой подход гарантирует вам актуальность всех ключей, которые вы получите на выходе.
Эта программа поможет вам увидеть наиболее популярные страницы вашего сайта, определить верную стратегию продвижения, основываясь на статистических данных. В конечном итоге вы можете выгрузить всю информацию в удобный формат, например, в таблицу Excel.
Я уверен, что купить программу определенно стоит. Если понять, как работать, то это может сэкономить существенную часть финансов и времени. Да и проекты с качественной семантикой будут давать больше отдачи, что также является плюсом.
Процесс парсинга в Кей Коллекторе
Сам процесс достаточно прост и не является чем-то сложным и выполняется в автоматическом режиме.
Первоначально нужно сразу же выставить нужное гео для парсинга, это делается в самом низу программы:
После этого нужно создать папки, куда будут помещаться спарсенные ключевые слова, папки создаются в левой колонке программы. Конечно можно парсить все в одну папку и потом делать группировку ключей, но логичнее и удобнее заранее поделить маски ключей по смыслу и парсить маски по папкам. Например: есть две маски ключей, которые хотим спарсить — вызов такси и заказать такси, для удобства дальнейшей работы с ключами, парсим маски не в общую папку, а в соответствующие две папки, чтобы ключи уже были отсортированы.
Кроме этого, если масок не много, то можно каждую папку назвать маской и тогда программа сделает парсинг по названию папки, что является очень удобным функционалом.
Для этого заранее создаем нужные папки и нажимаем на парсинг с вордстата. По умолчанию стоит галочка «Добавить в текущую группу», но нужно поставить галочку «Распределить по группам» и нажать на красную стрелочку, как показано на картинке. Здесь можно в каждую папку поместить нужные маски (т.е. не каждую маску парсить отдельно, а чтобы в одной папке были распарсено сразу несколько масок ключей); можно убрать не нужные папки и стоит заметить, что названия папок тоже будут распарсены (если этого вам не нужно просто убираем не нужное ключевое слово). Далее нажимаем на «Начать сбор» и происходит парсинг, после которого идет следующая работа — сбор минус слов, чистка ключей и их группировка:
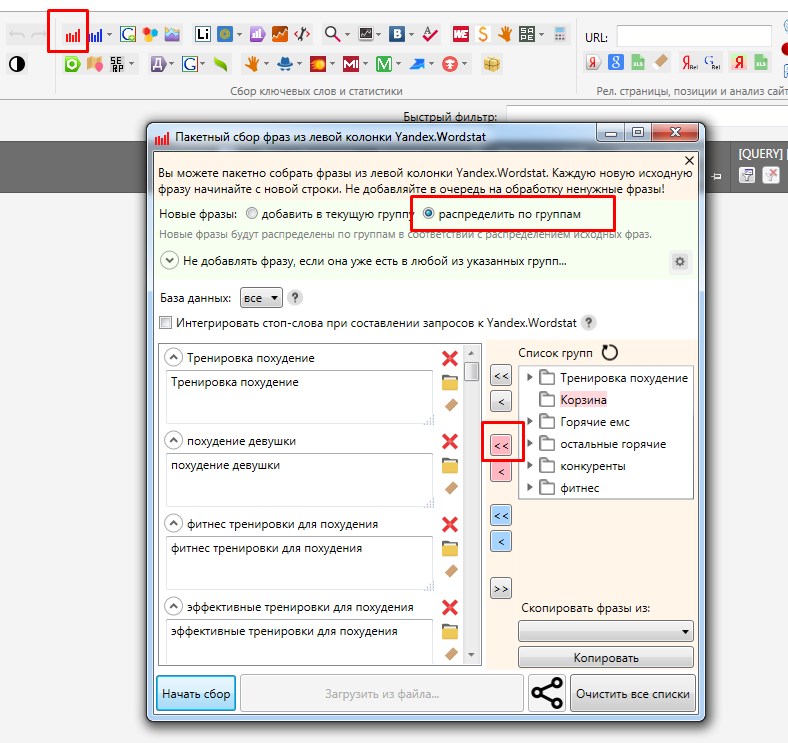
Сбор семантики в Key Collector
На примере группы запросов: “курсовая работа”, я покажу как я собираю семантику для своего сайта, с помощью кейколлектора.
1. Устанавливаем расширение для браузера “Serpstat Website SEO Checker”
3. Активируем расширение, и переходим во вкладку “Анализ страницы”. Там мы получаем ТОП-10 ключевых слов по URL. Копируем в ключевые слова в текстовый файл, удаляя лишнее.

4. Полученный список ключей переносим в текстовый файл.
5. Открываем кейколлектор. Вкладка: “Данные” — Прочее — “Планировщик задач”. Далее нажимаеv на шестеренку “Задать параметры”.
Выбираем сбор фраз из Яндекс Вордстат. Выбираем регион, в моем случае это Россия. Далее нажимаем на значок “Распределить по группам” — загружаем список наших ключей — нажимаем “Применить изменения”.

6. Далее добавляем в скрипт задачу: “Собрать поисковые подсказки Яндекс” В настройках с помощью желтых и зеленых папок переносим наши фразы.
Потом добавляем в скрипт: “Собрать прогноз из Яндекс Директ”. В настройках выбираем все наши группы, выбираем нужный регион, ставим галочки напротив всех частот. Для полной семантики, можно добавить ПС Google.
7. Нажимаем “Создать скрипт”, пишем имя для скрипта и нажимаем “Продолжить”. Все, теперь ждем пока спарсятся все ключи.
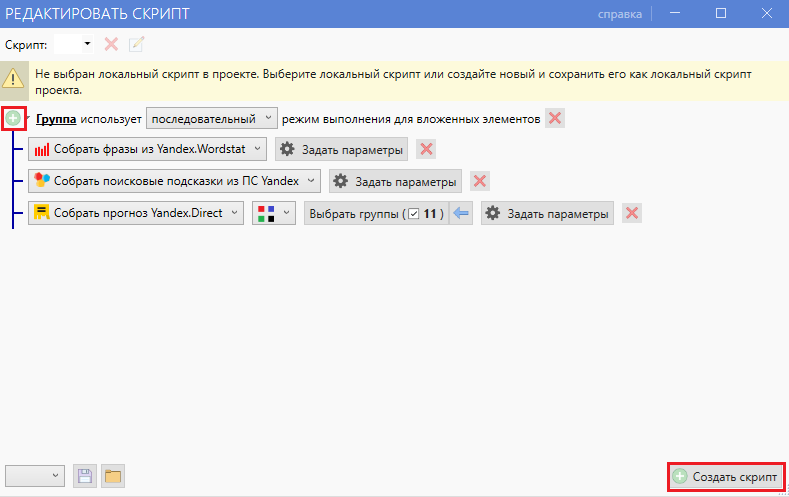
8. После того как Key Collector закончит сбор фраз и частотность, нам нужно удалить все запросы равные нулю. Включаем мультигруппы: выделяем все наши группы Ctrl+A и нажимаем F3.
В колонке с точной частотность настраиваем фильтр: равно 0.

9. Собранную семантику нужно очистить на предмет дублей. Переходим во вкладку: Главная — «Неявные дубли» — Найти. С помощью умной отметки выбираем запросы, далее нажимаем удалить и применить.
10. Далее с помощью функции “Минус Слова” удалить ненужные запросы, типа скачать торрент, порно, итд.
11. Теперь все оставшиеся фразы нам нужно перенести в одну, новую группу.
Выделяем все наши группы Ctrl+A — Вкладка данные — Копировать/перенести фразы. Перенести в «Новая группа». После чего все остальные группы можно удалять. Новую группу переименовываем в «Курсовая работа». Теперь у нас есть пул запросов, и можно переходить на этап кластеризации.
Сбор семантики
Вот мы и перешли к самому вкусному. Собирать ключи можно из левой и правой колонок Вордстата. Как вы наверняка знаете, в левой показываются запросы с вхождением ключевого слова. В правой же – похожие запросы.

В этом материале мы рассмотрим именно сбор из левой колонки. Итак, нажимаем на красную иконку, после чего у нас открывается такое окно.
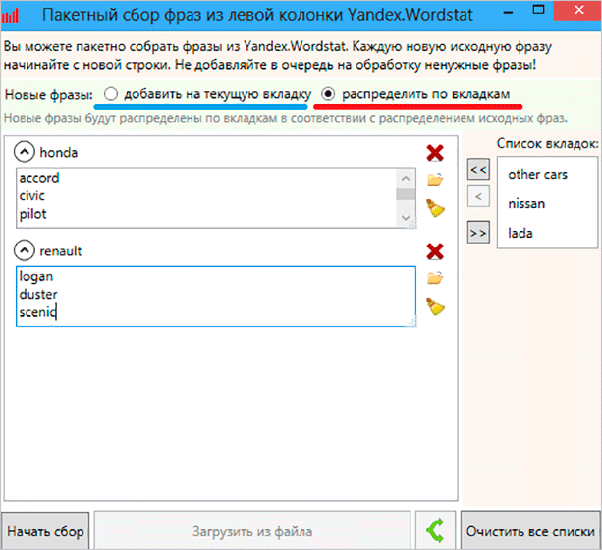
Здесь мы можем ввести все ключевые слова, которые нам нужны. Их можно разбить на вкладки и группы. Ключи можно вводить вручную, а можно просто выгрузить из файла.
После нажатия кнопки “Начать сбор” программа начнет свою работу. В зависимости от настроек и количества ключей этот процесс может занять определенное время. Иногда и по несколько часов. В конечном итоге вы получите список всех ключевых слов и фраз из левой колонки Вордстата.
Далее мы можем снять более точную частотность, потому как та, что будет доступна сразу после сбора, – ложная. Не стоит ей доверять и уж тем более делать какие-то выводы.
При сборе из правой колонки порядок действий тот же самый. Только ключей получится больше, в силу того, что в таблицу попадут все “похожие”.
Частотность
После сбора самой семантики, вы можете собрать частотность. Причем базовая частотность не даст нам особо полезной информации, поэтому нас интересует частотности с вхождением конкретных слов (“ “) и с точным вхождением (“!”)
Для сбора всех видов частотностей мы можем использовать одну кнопку.
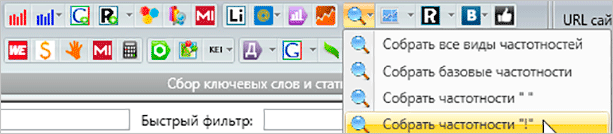
Съем более точных частотностей позволит вам получить наиболее правильные статистические данные о количестве запросов в Яндексе. Базовая вариация не отражает истинную суть, и чаще всего при составлении семантического ядра она игнорируется.
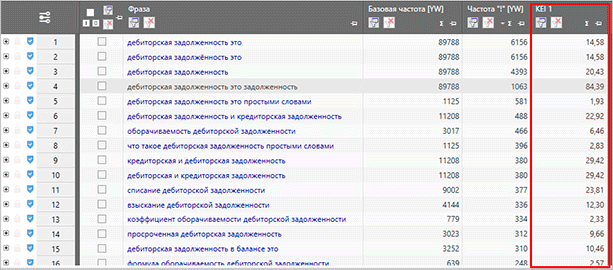
Именно сбор частотности в конечном итоге позволяет вам кластеризовать семантическое ядро по запросам: ВЧ, СЧ и НЧ. Исходя из этих данных, сеошники могут разделять ключи по группам, создавая для каждой отдельной статьи свою небольшую базу из тайтла и нескольких ключевых слов. Далее эта информация передается копирайтерам для написания статей. Сейчас такой способ является наиболее популярным при работе с информационными сайтами.
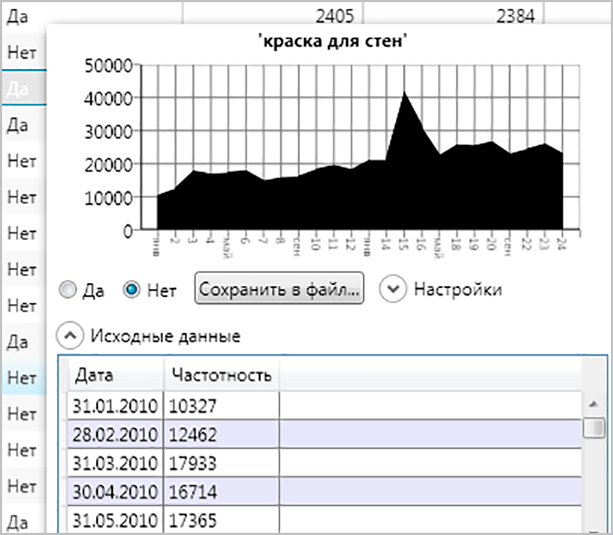
Сезонность
Сезонные запросы – это ключи, которые актуальны в какое-то время года или в какое-то конкретное время. Если вы собираете семантику для магазина с пляжными товарами, то вам нужно брать в расчет наибольший спрос, а именно в летнее время.
Сбор сезонности позволит вам определить, какие запросы в какое время пользуются наибольшей популярностью. Чтобы собрать эту информацию с помощью Кей Коллектора, найдите в меню иконок кнопку “Сбор ключевых слов и статистики”.
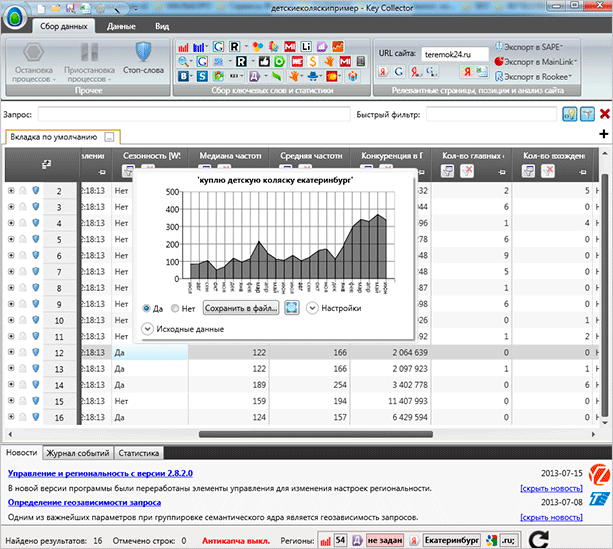
После завершения процесса на примере графика вы сможете увидеть популярность того или иного запроса в какой-то конкретный месяц.
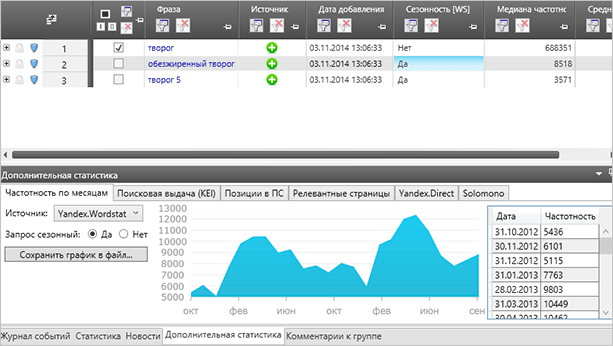
Вы можете получить данные по неделям, а не по месяцам, как это представлено на скриншоте. Для настройки используйте все ту же кнопку “Сбор ключевых слов и статистики”, она раскрывается, там вы и найдете соответствующий пункт.
При необходимости вы можете посмотреть более подробную информацию. Для этого просто кликните на нужной ячейке.
Борьба с погрешностями и операторы поиска
К сожалению, при работе в формонезависимых режимах возможны погрешности. Иногда программа считает близкие по смыслу слова одинаковыми, а иногда наоборот не улавливает связи между одним и тем же словом в разных склонениях.
Специальными операторы поиска позволяются исправить ошибки или уточнить его критерии.
Фиксация словоформы (точный поиск)
Если программа ошибочно принимает какое-то слово за искомое, вы можете зафиксировать проблемное минус-слово оператором !
- !Киев
- !кий
- !как
- !тянули !репку
Например, «Киев» и «кий» в упрощенном быстром режиме могут считаться равными, т.к. их неизменяемая часть «ки» совпадает в обоих словах. Или же «как» и «почему» может быть приняты за равнозначные слова в улучшенном режиме.
Для фиксации минус-фразы необходимо использовать оператор ! перед каждым словом фразы. Фиксировать отдельные слова минус-фразы не допускается.
Фиксация фразы (фразовый поиск)
При поиске минус-фраз, состоящих из нескольких слов, по умолчанию программа разрешает присутствие посторонних слов между словами искомой фразы. Оператор » » локально запрещает эту возможность.
- «заказать торт»
- «в банке»
Например, минус-фраза заказать торт (без кавычек) будет найдена в запросе «заказать свадебный бисквитный торт с кремом». Если добавить оператор » «, то минус-фраза будет найдена только в запросах вида «заказать торт на праздник» (слова искомой фразы не разделены посторонними словами).
Фиксация порядка слов
- заказать торт
- в банке
Например, минус-фраза заказать торт (без кавычек) будет найдена в запросе «торт на праздник заказать». Если добавить оператор , то минус-фраза будет найдена только в запросах вида «заказать праздничный торт» (слова искомой фразы следуют строго в заданном порядке).
Композиция операторов
Допускается использование различных операторов сразу, однако важен порядок их применения.
- Фразовая фиксация » »
- Точная фиксация !
Почему лучше не участвовать в складчине
Прежде всего необходимо понимать, что складчина — это объединение людей, которые решили получить максимально низкую цену путем покупки множества лицензий. Это частная инициатива, а не наши партнеры или реселлеры.
Как правило, покупка происходит на один адрес почты какого-то одного человека, который затем распределяет купленные лицензии среди участников складчины.
Владельцем ВСЕХ лицензий в этом случае является тот самый владелец почты, на которую оформляются приобретаемые совместно лицензии.
Вы не сможете купить лицензию вскладчину по скидке, а потом отделить ее на свою личную почту. Для этого потребуется доплата разницы до полной стоимости лицензии (весь смысл участия в складчине теряется), а также согласие владельца лицензии, которым вы пока еще не являетесь.
Таким образом, в случае потери контакта с данным лицом или просто его личным решением освободить себя от каких-либо обязательств перед участниками складчины (или же просто «кинуть» их) последние полностью теряют какие-либо возможности по управлению «своими» (на самом деле — нет) лицензиями.
В этом случае мы никак не можем помочь им восстановить какую-либо справедливость, т.к. это был их осознанный риск и решение доверить свои деньги третьему лицу.
В целях защиты наших конечных клиентов от потери денег и лицензий мы стараемся предотвращать такие складчины, т.к. уже несколько раз их организаторы просто пропадали, и на нас ложилась волна негодования от участников этих складчин. К сожалению, помочь мы им ничем не смогли, т.к. фактическим владельцем и плательщиком денег в нашу сторону был именно организатор. Соответственно, без его согласия никаких операций с его лицензиями мы делать не можем.
Какая вам разница, как мы купили лицензию: напрямую или в складчину?
Свое мнение мы отразили в обсуждении акции по легализации:https://vk.com/wall-62285053_9332
Приведем некоторые наши комментарии для понимания сути процессов, происходящих при покупке в складчину и пропаже ее организатора.
Был пользователь, который на форуме предлагал людям купить программу дешевле, чем продаем мы. При этом он покупал лицензию как «двадцатую» для себя, оформлял на себя, а тем, кто переводил ему деньги, просто передавал файл лицензии. Все лицензии были привязаны на его почту, а не на тех, кому он их передавал впоследствии.
Если нужно было поменять лицензию, люди обращались к нему, и он это производил со своей почты и заново высылал им файл.
Пользователь платит 1 раз и пользуется программой постоянно. Кто купил 6 лет назад и заплатил за нее 700 рублей — тот пользуется программой, обновлениями, саппортом, до сих пор. Никаких доп. «поборов» мы не проводим.
Владельцы складчин предлагают купить программу за 1300-1400 руб., при этом покупая ее у нас за 1200 руб. по накопительной скидке. Пользователь доволен — получил скидку в несколько сотен. Складчик доволен — получил 100-200 рублей прибыли. Мы получили не 1700 руб., а 1200 руб., но при этом пользователя мы обслуживаем также, ни в чем не ущемляя.
До определенной поры мы закрывали на это глаза, но на этой неделе пропал очередной такой организатор складчины, и мы получаем тучу негатива от пользователей, которые купили через него.
Оно нам надо? Мы как оказывали поддержку, так и оказываем, но не имеем никакого права отбирать у владельца складчины лицензии, ведь платил-то нам именно он, и заявка на его почту была.
В результате он пропал, пользователи льют на нас негатив, саппорт вместо развития программы и решения вопросов пользователей по пол дня отписывает в формате «война и мир» ситуацию, объясняя, кто владелец лицензии.
Есть крупная сео-контора. Она покупает, допустим, 20 лицензий на 20 сотрудников. Один из двадцати является руководителем отдела продвижения, он знает софт, он задает нам вопросы, мы на них отвечаем. Далее он обучает остальных 19 сотрудников работе с софтом. В результате мы выдали 20 лицензий и получили нагрузку в службу поддержки, равную 1 пользователю.
Теперь о складчине. Человек купил 20 лицензий, выдал 20 разным людям. В результате мы получили нагрузку на саппорт, равную 20 пользователям, но при этом НЕДОполучили средства на развитие программы.
Мы устали разгребать письма и звонки, которые происходят после того, как организатор ушел в запой/отпуск/офлайн/иной мир.
Сбор частотностей
После получения данных из Вордстата или других источников нужно собрать частотности, чтобы оценить спрос. На его основе будем делать группировку и составлять ТЗ.
Для этого есть 2 основных варианта.
- Можно собирать частотности с помощью кнопки «Сбор частотности из сервиса Yandex Wordstat». Это медленный вариант, он подходит для сбора частотностей фраз состоящих из 8 слов и более. В других случаях используйте следующий вариант.
- Лучше всего собирать частотность с помощью Yandex Direct. Программа будет обрабатывать слова не по одному, а целой пачкой зараз.
При сборе частотностей Директ можно указать, какие снимать и за какой период.
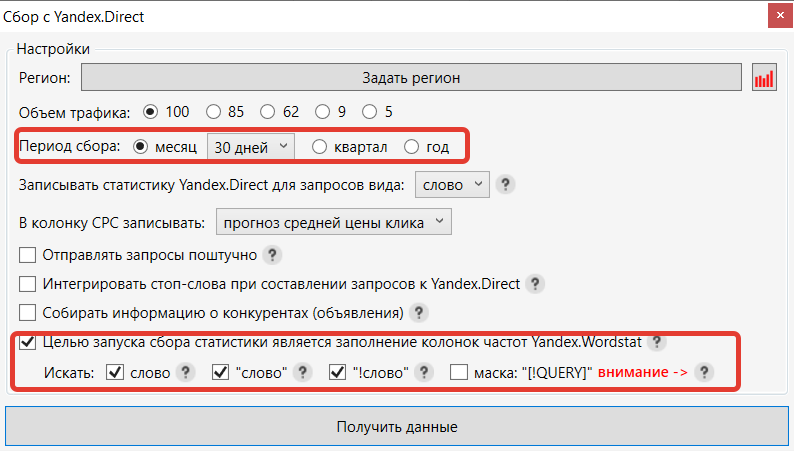
- Рекомендуется снимать частотности за последние 30 дней, если это не сезонные запросы. При съеме за другой период могут получиться не совсем адекватные цифры – видимо, Яндекс не хранит точные данные за более длительные периоды или выдает их в округленном виде.
- Съем фраз разных частотностей можно разбить на 2 или 3 этапа. Например, сначала снять базовую частотность (если добавлены запросы из других источников), отфильтровать по частотности и удалить запросы ниже определенного порога. Далее снять частотность в кавычках, снова отфильтровать запросы с неподходящей частотой и удалить их. И только потом снять самую точную частотность. Таким образом, процесс съема будет дешевле и быстрее.
Редактирование ячеек
Вы можете изменять значения ячеек в таблице. При этом редактировать можно как сами фразы, так и данные в колонках статистики (если они не заблокированы для редактирования).
Перед редактированием фраз убедитесь, что это разрешено в «Настройках — Интерфейс — Таблица данных — Управление таблицей».
Для редактирования фразы нажмите клавишу F2 или совершите двойной клик мышкой по фразе. Ячейка перейдет в режим редактирования.
В силу ограничения уникальности фраз в пределах одной группы допускается ввод только уникальных фраз (в случае нахождения полного дубликата операция редактирования будет отменена).
Для редактирования ячеек в остальных колонках можно поступить аналогичным образом. Однако в дополнение к этому также становится доступной контекстная вкладка«Таблица данных», где вы можете найти дополнительные инструменты для редактирования значений.

Вы можете изменить значения нескольких ячеек в одно действие. Для этого выделите ячейки и нажмите кнопку «Редактировать». В открывшемся диалоговом окне задайте желаемое значение и нажмите кнопку «OK».
Как установить программу на компьютер
Оплатите и скачайте программу на официальном сайте. Цена одной лицензии 1 800 рублей.

Запустите установочный файл скачанной программы и следуйте инструкции.
После установки нужно активировать лицензию:
- При запуске установленной программы появится окно с уникальным идентификатором (HID).
- Лицензия (файл lic.license) придет на почтовый ящик после оплаты, ее нужно положить в папку с программой. По умолчанию Кей Коллектор устанавливается в «Мои документы/Key Collector».
- Можно запускать программу и пользоваться.
Если возникли трудности, ищите всю информацию по инсталляции на сайте программы.
Выполнение поиска и работа с результатами
Итак, после выбора группы минус-слов, формирования списка минусации и установки настроек вы можете выполнить поиск.

По завершении поиска открывается временная мультигруппа с результатами.
В ленте инструментов при этом будет добавлена контекстная вкладка «Предпросмотр», которая позволит управлять временной мультигруппой.

Таблица результатов содержит колонку подсветки, где отображается подсказка по найденному минус-слову в исходной фразе, а само найденное минус-слово отображается в колонке «Минус-слово».
Вы можете работать с результатами поиска в мультигруппе как с обычной мультигруппой: сортировать данные, применять фильтры, отмечать и удалять строки, запускать парсинг и т.д.
В колонке«Группа»отображается название целевой группы, где была найдена фраза из указанных групп-источников. Вы можете перейти внутрь этой целевой группы, зажав клавишуCtrlи кликнув по ее названию.
Преимущества сервиса от Моаб очевидны:
— Глубина парсинга на площадке достаточно большая. Дополнительно, есть вариант выбора длины хвоста.
— Скорость выполнения исследования достаточно высокая. Для сравнения обычная обработка запроса «ОКНА» занимает 14 часов, а при использовании ресурса процесс заканчивается за 5 часов и приносит даже большее количество результатов.
— берёте пакет ПРО за 4999 рублей, а получаете почти бесконечный боезапас, полноценный Key Collector и огромное количество бонусов.
— Никакие капчи, прокси и прочие проблемы подборки вас не беспокоят. Просто нажимаете кнопку и получаете результат.
— 500 000 фраз — это объем, на википедию, не говоря уж о простых ресурсах.
Большой полюс в MOAB Tools — качество подбора фраз. Попробуйте в действии все функции на тарифе Free и убедитесь в возможностях сами. Лучше один раз потрогать, чем сто раз услышать.
Не упустите свой шанс и принимайте участие в акции тут.
SimpleSearch — поиск по сайту
Новая технология сбора семантики >
Сортировка и фильтрация данных
Сортировка данных
В таблице данных поддерживается сортировка по одной или нескольким колонкам (двойная сортировка).
Включить или отключить поддержку двойной сортировки можно в «Настройках — Интерфейс — Таблица данных — Управление таблицей».
Массово отсортировать все группы по какой-то колонке можно, зажав клавишу Shift. Если нужно установить условия только для выделенных групп, зажмите клавишу Ctrl.
Сортировка в мультигруппах
При работе с мультигруппами по умолчанию фразы в мультигруппе сортируются по порядку следования групп в панели управления группами.
Если вы хотите, чтобы в мультигруппе фразы сортировались по какой-либо колонке со статистикой дополнительно к порядку следования групп, то перед созданием мультигруппы примените для внутренних реальных групп массовую сортировку: зажмите Ctrl и кликните по заголовку нужной колонки. Затем активируйте режим мультигруппы.
Другие функции Кей Коллектора полезные для директолога:
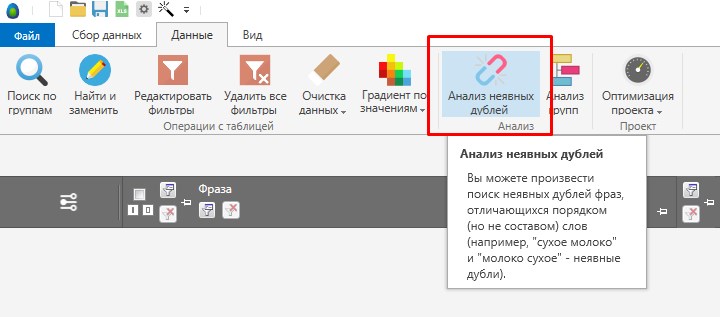
Удаление неявных дублей.
Если перейти во вкладку «Данные», то там будет полезная функция «Анализ неявных дублей», с помощью данной функции вы можете очистить собранное семантическое ядро не только от дублей, но и то неявных дублей. Например: как убрать комнату и как комнату убрать, будут считаться дублями. Программа покажет какие есть дубли, в каких группах, там же есть кнопка «Умная отметка», она автоматом выделяет один из дублей и вы его (или их удаляете), т.е. самостоятельно выделять и удалять дубли не надо, это делается в два клика.
Фильтры.
Каждый столбец в программе имеет самые различные фильтра. Например в столбце «Фразы» по фильтрам можно отыскать нужные ключевые слова, можно найти ключевые слова, которые состоят из определенного числа слов, это удобно при группировки ключей при обходе статуса «мало показов», когда в одну группу помещаются ключи с малой частотностью, но схожие по смыслу и написанию; в столбце «Базовая чистота», можно отфильтровать частотность по любому направлению (все ключи больше или равны 10, или меньше 5 и т.д.).

Быстрое составление списка минус слов.
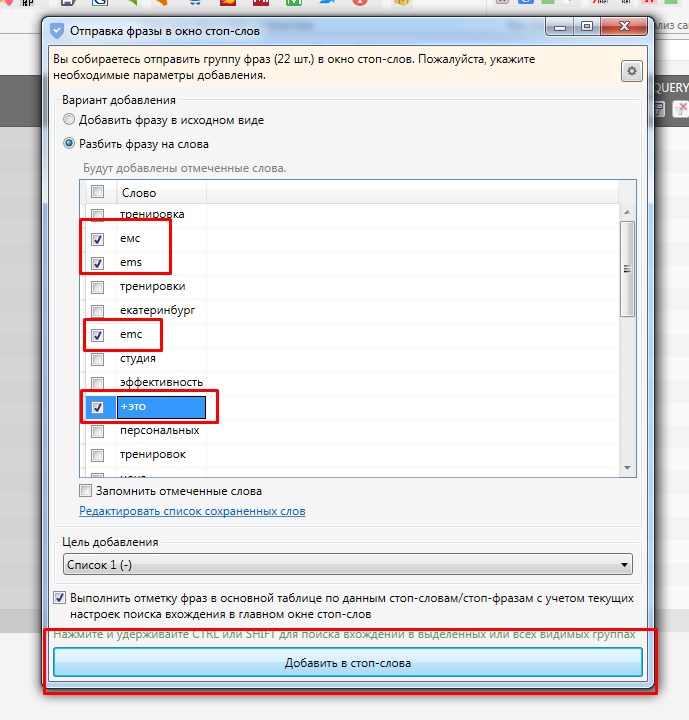
Для того, чтобы максимально комфортно собрать полный список минус слов, достаточно выделить все ключевые слова, кликнуть правой кнопкой мыши на них и выбрать «Отправить выделенные фразы в окно стоп-слов». После этого откроется список со всеми выделенными ключами, где отмечая нужные слова далее их помещаем в список минус-слов.
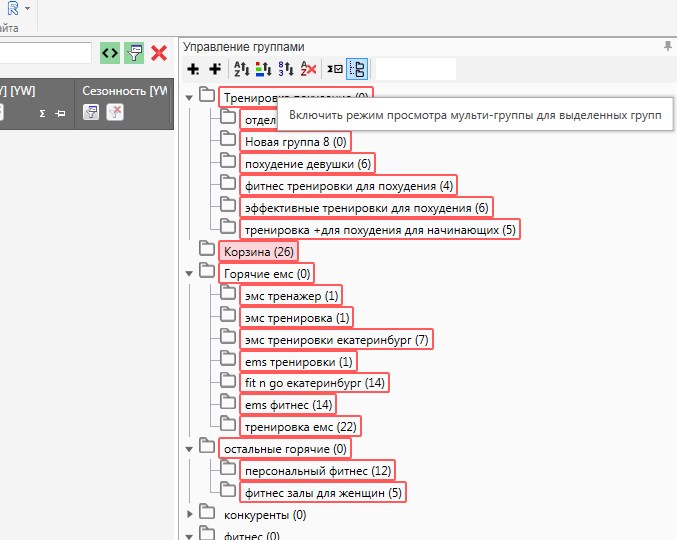
Режим мульти-группы.
Для того, чтобы выгрузить полученное семантическое ядро в единый эксель файл, или применить на все группы (папки) ключей минус слов и т.д. и т.п. необходимо сначала выделить все папки, и нажать на мульти-группы, и только тогда все папки как-бы объединяться в одну. Например: у вас много папок, и вы хотите выгрузить полное семантическое ядро в один единый файл в формате эксель. Если просто выделить все папки, то в эксель отправиться лишь одна папка, а для выбора и работы со всеми папками, как раз и нужен режим мульти-группа:
Сбор частотности ключевых слов.
С помощью Кей Коллектора можно не только парсить ключевые слова, но и собирать статистику с нужных ключевых слов. Это пригодиться тогда, когда вы делаете искусственную семантику и нужно ключи не спарсить, а просто узнать их частотность.
Для этого выбираем значок «Д», как указано на картинке, выбираем нужное гео именно в открывшейся вкладке и жмем «Получить данные»:

Удаление и сокрытие групп
Вы можете удалять или скрывать ненужные группы с фразами через контекстное меню или горячими клавишами.
При добавлении фраз (вручную или в процессе парсинга) при использовании режима добавления с пропуском существующих фраз в других группах фразы в скрытых группах будут считаться существующими (несмотря на то, что сама группа скрыта и не отображается в дереве групп), т.е. такие фразы будут пропущены как дубликаты, а фразы в помеченных на удаление группах будут считаться отсутствующими, т.к. такие фразы будут добавлены в таблицу.
Отличие помеченной на удаление группы от скрытой состоит также в том, что при закрытии проекта программа запросит подтверждение на безвозвратное удаление помеченных на удаление групп, когда как скрытые группы так и продолжат существовать в проекте.
Для удаления или сокрытия групп сперва необходимо выделить группы.
Для выделения подряд идущих групп удобно воспользоваться зажатой клавишей Shift и кликнуть сперва по первой, а затем по последней группе в требуемом диапазоне. При необходимости выделить подгруппы некоторых групп воспользуйтесь соответствующей кнопкой в контекстном меню заголовка группы или же на вкладке инструментов «Управление группами».
Восстановление групп
Для восстановления скрытых или помеченных на удаление групп нажмите кнопку в нижнем правом углу панели управления группами, отметьте нужные группы и нажмите «Восстановить».

Быстрый сбор СЯ
Теперь отличная новость: Сборщик и Моаб объединили свои усилия и работают в связке. Свой аккаунт на Mother Of All Businesses вы подключаете к Key Collector и спокойно собираете ядрышко на компьютере. Все настройки Моаба будут применены к вашей программулине, и сбор будет происходить без капчей и проксей.
Но интеграция это еще не самое интересное! В честь объединения усилий Моаб устраивает акцию: При покупке пакета ПРО, вы получаете лицензию на утилиту в подарок! Блок от MOAB Tools рассчитан на пятьсот тысяч проверок + лицензия На кей коллектор ценой в одну тысячу восемьсот рублей. Предложение действительно интересное. Дополнительным бонусом объявлено о скидках в у партнеров общим счетом почти пятьдесят тысяч рублей.
Список партнеров и скидок на их услуги действительно впечатляет. К примеру, в системе аналитики, автоматизации и управления проектами SEO CRM, а это неплохой старт для развития площадки. Есть в списке скидки на весьма полезные обучающие тренинги, на которых изучается семантика и контекстная реклама. В общем, дополнительные плюшки неплохие. Рекомендую не затягивать, а воспользоваться акцией.
Как подключить Моаб и выполнить быстрый сбор семанитики
Чтобы подключить Моабу к проге от LegatoSoft, нужно выполнить пару несложных шагов. Зарегистрироваться на портале, зайти в раздел API-ключ и нажать на кнопку скопировать. В КК зайти в настройки — парсинг и вставить ключ в строку Токкен. На панели увидите две кнопочки собрать фразы Вордстат и собрать частоты. Первая собирает слова из Яндекс.Вордстата, а вторая служит для подсчета частотности имеющихся фраз через службу.
Взаимодействие происходит в таком порядке. Вы пишете фразу в интерфейсе, эта задача после нажатия кнопки передается на обработку в Tools. КК ждет ответа на поставленную задачу. Как только задание обработается на сервисе, данные тут же поступают на ваш рабочий стол. Ход выполнения задачи отображается на вкладке статистика и в отдельном событийном журнале. Никакой лишней нагрузки на ваш комп и канал Интернет не возлагается.
Если кей коллектор у вас уже есть, то можно не заморачиваться с полным Про, а попробовать любой другой подешевле. Если проги нет, то не раздумывайте, а берите полный набор. Это очень удобно. Как бы вы не старались, а чтобы разобраться с программой у вас уйдет пара дней, или неделя. Воспользовавшись акцией, вы можете сходу начать работу с семантикой, а выигранное время потратить на изучение бонусных программ. Ограничений по времени в этом сервисе нет, полмиллиона ключевиков вам хватит надолго для подпитки своего ядра.
Заключение
Key Collector – сложная, многофункциональная утилита, которую вот так вот просто не освоить. Для более полного понимания чаще всего проходят специальное обучение. На курсах получают уроки по работе с семантикой и навыки по Кей Коллектору или аналогам. Поэтому сразу изучить эту программу полностью не получится.

Необходимый минимум в этой небольшой статье я вам дал. При помощи модуля Яндекс Вордстат вы сможете осуществлять съем семантического ядра, получать все виды частотностей и использовать это для составления крутых материалов. Имейте в виду, что сбор семантического ядра – работа тяжелая. Она требует серьезного подхода, и ни один инструмент не будет делать за вас абсолютно всю работу.
В случае с Кей Коллектором вам определенно придется покопаться с настройками. Многие пользователи изначально уделяют не так много времени этому, за что впоследствии расплачиваются неправильно составленной семантикой
Не совершайте ошибок, старайтесь уделить должное внимание настройкам и изучению особенностей работы этой утилиты
Если вы хотите разбираться не только в сборе семантического ядра, но еще и в создании крутых сайтов и их монетизации, я могу предложить вам пройти курс Василия Блинова “Как создать блог”. В нем будут рассмотрены все нюансы работы вебмастера, в том числе и такого аспекта, как сбор семантического ядра. По программе Key Collector вы тоже пройдетесь, получив более полные знания о работе в нем. Доступ на первый уровень предоставляется абсолютно бесплатно, поэтому не упустите свой шанс.